Category: Uncategorized
INTRODUCTION
“Zombies” may be pure fiction in Hollywood movies, but they are a very real concern in an area where most individuals would least expect – trademark law. A long-established doctrine in U.S. trademark law deems a mark to be considered abandoned when its use has been discontinued and where the trademark owner has no intent to resume use. Given how straightforward this doctrine seems, it is curious why the doctrine of residual goodwill has been given such great importance in trademark law.
Residual goodwill is defined as customer recognition that persists even after the last sale of a product or service have concluded and the owner has no intent to resume use. Courts have not come to a clear consensus on how much weight to assign to residual goodwill when conducting a trademark abandonment analysis. Not only is the doctrine of residual goodwill not rooted in federal trademark statutes, but it also has the potential to stifle creativity among entrepreneurs as the secondhand marketplace model continues to grow rapidly in the retail industry.
This dynamic has led to a phenomenon where (1) courts have placed too much weight on the doctrine of residual goodwill in assessing trademark abandonment, leading to (2) over-reliance on residual goodwill, which can be especially problematic given the growth of the secondhand retail market, and finally, (3) over-reliance on residual goodwill in the secondhand retail market will disproportionately benefit large corporations over smaller entrepreneurs.
A. The Over-Extension of Residual Goodwill in Trademark Law
A long-held principle in intellectual property law is that “[t]rademarks contribute to an efficient market by helping consumers find products they like from sources they trust.” However, the law has many forfeiture mechanisms that can put an end to a product’s trademark protection when justice calls for it. One of these mechanisms is the abandonment doctrine. Under this doctrine, a trademark owner can lose protection if the owner ceases use of the mark and cannot show a clear intent to resume use. Accordingly, the abandonment doctrine encourages brands to keep marks and products in use so that they cannot merely warehouse marks to siphon off market competition.
The theory behind residual goodwill is that trademark owners may deserve continued protection even after a prima facie finding of abandonment because consumers may associate a discontinued trademark with the producer of a discontinued product. This doctrine is primarily a product of case law rather than deriving from trademark statutes. Most courts will not rely on principles of residual goodwill alone in evaluating whether a mark owner has abandoned its mark. Instead, courts will often consider residual goodwill along with evidence of how long the mark had been discontinued and whether the mark owner intended to reintroduce the mark in the future.
Some courts, like the Fifth Circuit, have gone as far as completely rejecting the doctrine of residual goodwill in trademark abandonment analysis and will focus solely on the intent of the mark owner in reintroducing the mark. These courts reject the notion that a trademark owner’s “intent not to abandon” is the same as an “intent to resume use” when the owner is accused of trademark warehousing. Indeed, in Exxon Corp. v. Humble Exploration Co., the Fifth Circuit held that “[s]topping at an ‘intent not to abandon’ tolerates an owner’s protecting a mark with neither commercial use nor plans to resume commercial use” and that “such a license is not permitted by the Lanham Act.”
The topic of residual goodwill has gained increased importance over the last several years as the secondhand retail market has grown. The presence of online resale and restoration businesses in the fashion sector has made it much easier for consumers to buy products that have been in commerce for several decades and might contain trademarks still possessing strong residual goodwill. Accordingly, it will be even more crucial for courts and policymakers to take a hard look at whether too much importance is currently placed on residual goodwill in trademark abandonment analysis.
B. Residual Goodwill’s Increasing Importance Given the Growth of the Secondhand Resale Fashion Market
Trademark residual goodwill will become even more important for retail entrepreneurs to consider, given the rapid growth in the secondhand retail market. Brands are using these secondhand marketplaces to extend the lifecycles of some of their top products, which will subsequently extend the lifecycle of their intellectual property through increased residual goodwill.
Sales in the secondhand retail market reached $36 billion in 2021 and are projected to nearly double in the next five years to $77 billion. Major brands and retailers are now making more concerted efforts to move into the resale space to avoid having their market share stolen by resellers. As more large retailers and brands extend the lifecycle of their products through resale marketplaces, these companies will also likely extend the lifespan of their intellectual property based on the principles of residual goodwill. In other words, it is now more likely for residual goodwill to accrue with products that are discontinued by major brands and retailers now since those discontinued products are made available through secondhand marketplaces.
The impact of the secondhand retail market on residual goodwill analysis may seem like it is still in its early stages of development. However, the recent Testarossa case, Ferrari SpA v. DU , out of the Court of Justice of the European Union is a preview of what may unfold in the U.S. In Testarossa, a German toy manufacturer challenged the validity of Ferrari’s trademark for its Testarossa car model on the grounds that Ferrari had not used the mark since it stopped producing Testarossas in 1996. While Ferrari had ceased producing new Testarossa models in 1996, it had still sold $20,000 in Testarossa parts between 2011 and 2017. As a result, the CJEU ultimately ruled in Ferrari’s favor and held that production of these parts constituted “use of that mark in accordance with its essential function” of identifying the Testarossa parts and where they came from.
Although Ferrari did use the Testarossa mark in commerce by selling car parts associated with the mark, the court’s dicta in the opinion referred to the topic of residual goodwill and its potentially broader applications. In its reasoning, the CJEU explained that if the trademark holder “actually uses the mark, in accordance with its essential function . . . when reselling second-hand goods, such use is capable of constituting ‘genuine use.’”
The Testarossa case dealt primarily with sales of cars and automobile parts, but the implications of its ruling extend to secondhand retail, in general. If the resale of goods is enough to qualify as “genuine use” under trademark law, then this provides trademark holders with a much lower threshold to prove that they have not abandoned marks. This lower threshold for “genuine use” in secondhand retail marketplaces, taken together with how courts have given potentially too much weight to residual goodwill in trademark abandonment analyses, could lead to adverse consequences for entrepreneurs in the retail sector.
C. The Largest Brands and Retailers Will Disproportionately Benefit from Relaxed Trademark Requirements
The increasingly low thresholds for satisfying trademark “genuine use” and for avoiding trademark abandonment will disproportionately benefit the largest fashion brands and retailers at the expense of smaller entrepreneurs in secondhand retail. Retail behemoths, such as Nike and Gucci, will disproportionately benefit from residual goodwill and increasingly relaxed requirements for trademark protection since these companies control more of their industry value systems. This concept will be explained in more detail in the next section.
Every retail company is a collection of activities that are performed to design, produce, market, deliver, and support the sale of its product. All these activities can be represented using a value chain. Meanwhile, a value system includes both a firm’s value chain and the value chains of all its suppliers, channels, and buyers. Any company’s competitive advantages can be best understood by looking at both its value chain and how it fits into its overall value system.
In fashion, top brands and retailers, such as Nike and Zara, sustain strong competitive advantages in the marketplace in part because of their control over multiple aspects of their value systems. For example, by offering private labels, retailers exert control over the supplier portion of their value systems. Furthermore, by owning stores and offering direct-to-consumer shipping, brands exert control over the channel portion of their value systems. These competitive advantages are only heightened when a company maintains tight protection over their intellectual property.
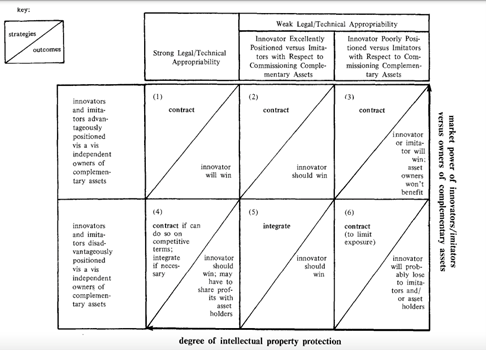
As portrayed in the figure below , companies maintain the strongest competitive advantages in cell one when they are advantageously positioned relative to owners of complementary assets, and they maintain strong intellectual property protection. In such situations, an innovator will win since it can derive value at multiple sections of its value system using its intellectual property.
CONCLUSION
Although there is little case law on the relevance of residual goodwill and secondhand retail marketplaces, it is only a matter of time until the largest fashion brands and retailers capitalize on increasingly low thresholds for demonstrating trademark “genuine use.” Courts and policymakers should now stay alert of these potential issues when dealing with trademark abandonment matters.
Rohun Reddy is a third-year JD-MBA student at the Northwestern Pritzker School of Law.
In August 2020, Marlene Stollings, the head coach of Texas Tech Women’s Basketball Team, allegedly forced her players to wear heart rate monitors during practice and games. Stollings would subsequently view the player data and reprimand each player who did not achieve their target heart rates. It could be argued that Stollings was simply pushing her players to perform better, however former player Erin DeGrate described Stollings’ use of the data as a “torture mechanism.” This is just one reported example of how athletic programs use athlete data collected from wearable technology to the student athlete’s detriment.
As of 2021 the market for wearable devices in athletics has a $79.94 billion valuation and is expected to grow to $212.67 billion by 2029. The major market competitors in the industry consist of Nike, Adidas, Under Armour, Apple, and Alphabet, Inc. so the expected growth comes as no surprise. Some wearable technology is worn by everyday consumers to simply track how many calories they have burned in a day or whether they met their desired exercise goals. On the other hand, professional and college athletes use wearable technology to track health and activity data to better understand their bodies and gain a competitive edge. While professional athletes can negotiate which types of technology they wear and how the technology is used through their league’s respective collective bargaining agreement, collegiate athletes do not benefit from these negotiation powers. Universities ultimately possess a sort of “constructive authority” to determine what kind of technology students wear, what data is collected, and how that data is used without considering the student athlete’s level of comfort. This is because if the student-athlete chooses to-opt out of wearable technology usage it may hinder their playing time or lead to being kicked off the team.
Studies show that collecting athlete biometric data has a positive effect on a player’s success and helps reduce possible injury. For instance, professional leagues utilize wearables for creating heat maps to analyze an athlete’s decision-making abilities. The Florida State Seminole basketball program also routinely uses wearables to track and monitor early signs of soft tissue damage which helped reduce the team’s overall injury rate by 88%. However, there are significant trade-offs including the invasion of an athlete’s privacy and possible misuse of the data.
Section I of this article will examine the different types of information collected from athletes and how that information is being collected. Section II will discuss a college athlete’s right to privacy under state biometric laws. Section III will discuss how data privacy laws are changing with respect to collecting athlete biometric data. Last, section IV will discuss possible solutions to collecting biometric data.
II. What Data is Collected & How?
Many people around the country use Smart Watch technology such as Fitbits, Apple Watches, or Samsung Galaxy Watches to track their everyday lifestyle. Intending to maintain a healthy lifestyle, people usually allow these devices to monitor the number of steps taken throughout the day, how many calories were burned, the variance of their heart rate, or even their sleep schedule. On the surface, there is nothing inherently problematic about this data collection, however, biometric data collected on college athletes is much more intrusive. Athletic programs are beginning to enter into contractual relationships with big tech companies to provide wearable technology for their athletes. For example, Rutgers University football program partnered with Oura to provide wearable rings for their athletes. Moreover, the types of data these devices collect include blood oxygenation levels, glucose, gait, blood pressure, body temperature, body fatigue, muscle strain, and even brain activity. While many college athletes voluntarily rely on wearable technology to develop a competitive edge, some collegiate programs now mandate students wear the technology for the athletic program to collect the data. Collegiate athletes do not have the benefit of negotiations or the privileges of a collective bargaining agreement, but the athletes do sign a national letter of intent which requires a waiver of certain rights in order to play for the University. Although college athletes have little to no bargaining power, they should be given the chance to negotiate this national letter of intent to incorporate biometric data privacy issues because it is ultimately their bodies producing the data.
II. Biometric Privacy Laws
Currently, there are no federal privacy laws on point that protect collecting student athlete biometric data. Nonetheless, some states have enacted biometric privacy statutes to deal with the issue. Illinois, for example, which houses thirteen NCAA Division I athletic programs, authorized the Biometric Information Privacy Act (BIPA) in 2008. BIPA creates standards for how companies in Illinois must handle biometric data. Specifically, BIPA prohibits private companies from collecting biometric data unless the company (1) informs the individual in writing that their biometric data is being collected or stored, (2) informs the individual in writing why the data is being collected along with the duration collection will continue for and (3) the company receives a written release from the individual. This is a step in the right direction in protecting athletes’ privacy since the statute’s language implies athletes would have to provide informed consent before their biometric data is collected. However, BIPA does not apply to universities and their student-athletes since they fall under the 25(c) exemption for institutions. Five other Illinois courts, including a recent decision in Powell v. DePaul University, explain the 25(c) exemption extended to “institutions of higher education that are significantly engaged in financial activities such as making or administering student loans.”
So, although Illinois has been praised for being one of the first states to address the emerging use of biometric data by private companies, it does not protect collegiate athletes who are “voluntarily” opting into the wearable technology procedures set by their teams.
III. Data Collection Laws are Changing
While BIPA does not protect collegiate athletes, other states have enacted privacy laws that may protect student-athletes. In 2017 the state of Washington followed Illinois’ footsteps by enacting its own biometric privacy law that is substantively similar to the provisions in BIPA. But the Washington law contains an expanded definition of what constitutes “biometric data.” Specifically, the law defines biometric identifiers as “data generated by automatic measurements of an individual’s biological characteristics, such as a fingerprint, voiceprint, eye retinas, irises or other unique biological patterns or characteristics that are used to identify a specific individual.” By adding the two phrases, “data generated by automatic measurements of an individual’s biological characteristics,” and “other biological patterns or characteristics that is used to identify a specific individual,” the Washington law may encompass the complex health data collected from student-athletes. The language in the statute is broad and thus likely covers an athlete’s biometric data because it is unique to that certain individual and could be used as a characteristic to identify that individual.
IV. Possible Solutions to Protect Player Biometric Data
Overall, it’s hard to believe that biometric data on student-athletes will see increased restrictions any time soon. There is too much on the line for college athletic programs to stop collecting biometric data since programs want to do whatever it takes to gain a competitive edge. Nonetheless, it would be possible to restrict who has access to athletes’ biometric data. In 2016, Nike and the University of Michigan signed an agreement worth $170 million where Nike would provide Michigan athletes with apparel and in return, Michigan would allow Nike to obtain personal data from Michigan athletes through the use of wearable technology. The contract hardly protected the University’s student-athletes and was executed in secrecy seeing its details were only revealed after obtaining information through the Freedom of Information Act. Since the University was negotiating the use of the student athlete’s biometric data on the athlete’s behalf, it can likely be assumed that the University owns the data. Therefore, athletes should push for negotiable scholarship terms allowing them to restrict access to their biometric data and only allow the athletic program’s medical professionals to obtain the data.
One would think that HIPAA protects this information from the outset. Yet there is a “general consensus” that HIPAA does not apply to information collected by wearables since (a) “wearable technology companies are not considered ‘covered entities’, (b) athletes consent to these companies having access to their information, or (c) an employment exemption applies.” Allowing student-athletes to restrict access before their college career starts likely hinders the peer pressure received from coaches to consent to data collection. Further, this would show they do not consent to companies having access to their information and could trigger HIPAA. This would also cause the information to be privileged since it is in the hands of a medical professional, and the athlete could still analyze the data with the medical professional on his or her own to gain the competitive edge biometric data provides.
Anthony Vitucci is a third-year law student at Northwestern Pritzker School of Law.
Introduction
News headlines about facial recognition technology primarily focus on the government’s use and misuse of the technology. Likewise, technology companies and legislators frequently advocate against the government’s use of facial recognition tools to conduct mass surveillance or generate leads in investigations. For example, following widespread claims of the technology’s racial bias, Amazon, IBM, and Microsoft announced that they would stop selling facial recognition tools to law enforcement agencies. And following the arrest of an innocent black man who was falsely identified by facial recognition, major cities like San Francisco and Boston banned law enforcement from using the technology.
However, as industry commentators focus on the government’s use of facial recognition tools, private businesses in the U.S. regularly deploy facial recognition technology to secretly surveil their customers. Companies rely on the technology to gather information about customers’ identities and demographics to tailor their marketing strategies, monitor customers within stores, or sell the information to third parties. Since there are no federal regulations governing the technology, commercial uses of facial recognition technology remain relatively unchecked, even as companies invade their customers’ privacy rights without any warning.
How Does Facial Recognition Technology Work?
Based on photos or still images, facial recognition technology scans, maps, and analyzes the geometry of a person’s face to verify their identity or collect information about their behavior. When mapping a face, the technology creates a mathematical formula — called a facial signature — based on the person’s distinct facial features, such as the distance between their eyes. Facial recognition systems can create and store facial signatures for each scanned image containing a face. When a user uploads a new photo, the system cross-references the generated facial signature with existing ones in the database and can verify the person’s identity with a matched signature.
Businesses have created databases of facial signatures to identify customers of interest in future video footage. In addition, businesses can use facial recognition software from companies like Clearview AI, which cross-references an uploaded photo against billions of public images to verify a person’s identity. Clearview AI is known to offer free trials of its software, luring businesses and rogue employees into using the technology. With such easy access to facial recognition software, private use of the technology has proliferated, hardly slowed by regulatory barriers.
Commercial Uses of Facial Recognition Technology
No matter the industry, facial recognition can help businesses glean more information about their customers, make informed business decisions, and increase their revenues. Shopping malls and mega-stores like Macy’s, Rite-Aid, Apple, and Walmart have used facial recognition to identify shoplifters, target loyal customers, and track customers’ reactions within the store. Amazon has sold facial recognition technology that assesses customers’ faces to discover whether they are attentive or indifferent to certain displays. While customers are surely aware these mega-stores have security cameras, they are likely unaware these stores may know their name, home address, how many times they’ve frequented the location, and whether they are happy with their in-store experience. Outside of retail stores, in cities like Miami, thousands of Uber and Lyft drivers have digital tablets in their backseats that use facial recognition technology to assess a rider’s age, gender, and demographics, in order to display ads tailored to the rider’s perceived characteristics.
In states without biometric privacy laws, any citizen who shops at a mall or grocery store, or attends a concert or sports game, will likely be the subject of unsuspecting facial recognition. Additionally, facial recognition tools can even identify an individual who rarely shows their face in public. Clearview AI created a facial recognition database by scraping ten billion images from public websites. Clearview analyzed the images and developed facial signatures for nearly half the U.S. population.
As of 2020, more than 200 companies had accounts with Clearview, including professional sports leagues, casinos, fitness centers, and banks. These companies can upload a photo of an individual’s face — pulled from security footage or driver’s licenses — and cross-reference it against Clearview’s database to find a match. With limited regulation and easy access to facial recognition tools, consumers will face the technology’s adverse consequences, such as misidentifications and loss of privacy rights.
Misidentifications and Privacy Risks
The accuracy of facial recognition technology to correctly identify a person depends on their age, gender, or race. Research from the National Institute of Standards and Technology revealed that facial recognition systems are less accurate when identifying people of color. The algorithms are more likely to misidentify African Americans, Native Americans, and Asians compared to Caucasians. Researchers also have found these algorithms to be less accurate when identifying women, transgender individuals, and children.
Misidentification can carry damaging consequences to an individual’s liberty and dignity. Robert Williams, the black man who was wrongfully arrested based on a facial recognition match, was a victim of misidentification. These same misidentifications are likely occurring at private establishments, where security guards use the technology to scan for known criminals and remove purported “matches” from their stores.
In addition to misidentifications, facial recognition technology intrudes on an individual’s right to privacy. The technology allows companies to identify customers without their consent, collecting information about customers’ demographics and preferences. Furthermore, companies that store facial templates are subject to data breaches, where thousands of their customers’ faceprints could become compromised. Unlike online passwords, a stolen faceprint is indefinitely compromised — a customer cannot change their faceprint. Last year, thousands of scammers in the U.S. tried using stolen faceprints to fraudulently obtain government-assistance benefits. As facial recognition technology grows, bad actors will attempt to use stolen faceprints for financial gain.
Federal, State, and Local Regulations
There are no federal regulations curbing the private use of facial recognition technology, but Congress’s interest in regulating the technology is increasing. Legislators introduced three separate bills to regulate facial recognition technology in the past few years, yet none passed the introduction stage.
One of the bills introduced in the Senate, the Commercial Facial Recognition Privacy Act, would have required all private entities to obtain explicit consent from customers before collecting faceprint data. The bill’s consent requirement is based on the Illinois Biometric Information Privacy Act (BIPA), one of only three state-enacted biometric privacy laws.
BIPA requires businesses that use facial recognition technology to obtain consent from consumers before collecting their faceprint data. It also requires these businesses to provide information about how they protect and store the biometric data. BIPA permits individuals to sue companies who violate any requirement in the statute and offers significant statutory damages for violations. In February 2021, Facebook paid out $650 million to settle a BIPA class-action lawsuit. To date, more than 800 BIPA class action lawsuits have been filed against Illinois businesses.
Despite BIPA’s teeth, businesses can freely use facial recognition in almost every other state. Texas and Washington are the only other states with biometric privacy laws that regulate commercial use of the technology. Yet, neither state permits citizens to sue companies for violating the statute, meaning there is much less pressure to comply. Enforcement lies with each state’s attorney general, who can impose civil penalties on violators.
Fortunately, bans on private use are growing at the city level. In September 2020, Portland, Oregon, became the first municipality to ban private entities from using facial recognition in public places, such as shopping malls. Since then, two other cities have followed suit. New York City now requires commercial establishments to post notices when using facial recognition technology, and Baltimore banned all private sector use of the technology, even subjecting violators to criminal penalties. The recent wave of restrictions at the city level indicates that regulations may first arise where the commercial sector flourishes — in major cities.
Calls for Regulation and Future Outlook
Despite the pervasive commercial use of facial recognition technology, sixty percent of Americans are unaware that retail stores use the technology. This lack of awareness stems in part from the lack of regulation. Aside from a few states and a handful of cities, most businesses are unregulated: free to implement facial recognition tools without warning their customers. So far, calls for regulation have primarily come from companies that have developed facial recognition technology themselves: Microsoft, IBM, and Amazon. While these calls may be aimed at influencing friendly regulations, Microsoft’s President Brad Smith has called for legislation requiring stores to provide notice and obtain consent, similar to BIPA’s consent requirement. As BIPA has revealed, requiring businesses to obtain consent from consumers would at least hold businesses accountable for their facial recognition uses.
Nevertheless, some businesses may not wait for enacted legislation before shelving their facial recognition products. In November 2021, Meta announced that Facebook will no longer use facial recognition software and plans to delete the faceprint data of one billion Facebook users. Meta’s decision was motivated by concerns about the technology’s “place in our society.” This drastic move may prompt other industry leaders to start influencing the future treatment of facial recognition technology, with the hopes of clearing up the current regulatory uncertainty that threatens innovation and investment. While some may question Meta’s sincerity or true motives, its decision could foreshadow an era of much-needed regulatory action.
Michael Willian is a third-year law student at Northwestern Pritzker School of Law.
I. Introduction
The COVID-19 pandemic has brought the issues of personal privacy and biometric data to the forefront of the American legal landscape. In an increasingly digital world, privacy laws are more important than ever. This reality is especially true in the context of remote workplaces, where employers have facilitated a digital migration through a variety of means. The platforms employers use have the propensity to violate personal privacy through the capture and storage of sensitive biometric information. In response, states across the nation are exploring solutions to the potential privacy issues inherent in the collection of biometric data. One of the first states to do so was Illinois, enacting a standalone biometric privacy statute in 2008: the Illinois Biometric Information Privacy Act (“BIPA”). Today, BIPA is more relevant than ever and should act as a statutory blueprint for states looking to protect personal privacy and biometric data amid a global pandemic. Ultimately, though, BIPA must be supplemented by federal legislation drafted in its likeness to effectively protect individuals’ privacy on a national level.
II. Background of the Biometric Information Privacy Act
To fully understand BIPA and all its implications, one must appreciate the context in which it was enacted. The Illinois legislature passed BIPA in October 2008. The Act was passed in the immediate wake of the bankruptcy of Pay By Touch, a company which operated the largest fingerprint scan system in Illinois. Pay By Touch’s pilot program was used in grocery stores and gas stations, and its bankruptcy left users unsure of what would become of their biometric data – i.e., their fingerprints. “Biometric data – a person’s unique biological traits embodied in not only fingerprints but also voice prints, retinal scans, and facial geometry – is the most sensitive data belonging to an individual.”
Understandably, private citizens in Illinois and across the country want to safeguard their sensitive biometric data. With potential issues such as identity theft and data manipulation more prevalent than ever, people have plenty of incentives to ensure their unique identifiers stay private. In response to those concerns, legislatures have passed statutes to address biometric data and personal privacy. BIPA represents one of the most stringent of such acts in the country, setting strict requirements for the management of biometric identifiers in Illinois.
BIPA defines “biometric identifier” as (1) a retina or iris scan, (2) fingerprint, (3) voiceprint, or (4) a scan of hand or face geometry. Further, “biometric information” refers to any information, regardless of how it is captured, converted, stored, or shared, based on an individual’s biometric identifier used to identify an individual. The requirements outlined in Section 15 of the Act – which addresses the retention, collection, disclosure, and destruction of biometric data – implicate a slew of potential legal issues. The section stipulates that a private entity can collect a person’s biometric data only if it first informs the subject that a biometric identifier is being collected, informs them of the specific purpose and length of term it is being collected for, and receives a written release from the subject.
Further, the Act outlines the following concerning retention of such data:
(a) A private entity in possession of biometric identifiers or biometric information must develop a written policy, made available to the public, establishing a retention schedule and guidelines for permanently destroying biometric identifiers and biometric information when the initial purpose for collecting or obtaining such identifiers or information has been satisfied or within 3 years of the individual’s last interaction with the private entity, whichever comes first.
Thus, BIPA represents a statute narrowly aimed at maintaining the security of biometric data. While BIPA was relatively unknown in Illinois between 2008-2015, a wave of litigation has since swept through the state as employees began suing their employers. Such litigation was seemingly inevitable, as BIPA provides sweeping protection for individuals against biometric data abuse. The complexities of such issues have become clearer and potential legislative solutions to them even more important in the midst of a global pandemic.
III. Personal Privacy & Biometric Data in the COVID-19 Pandemic
The issues surrounding data privacy have become increasingly relevant in the ongoing COVID-19 pandemic, which effectively digitized the workplace as we know it. As the pandemic raged in the early months of 2020, workplaces around the globe were suddenly forced to digitally migrate to an online work environment. An inevitable result of newfound online worksites has been an increase in the utilization of biometric data. In an effort to facilitate remote work, companies have had to make work-related information accessible online. Employment attorney Eliana Theodorou outlines the ensuing issues for companies undertaking such efforts in an article entitled “COVID-19 and the Illinois Biometric Information Privacy Act.” For example, Theodorou writes, “Some of these platforms involve video recording or access by fingerprint, face scan, or retina or iris scan, which may result in the capture and storage of sensitive biometric information.” Thus, the collection and retention of biometric data has necessarily increased during the pandemic as companies made information accessible remotely when they shifted online.
Potential privacy issues accompanying the storage of biometric data will become even more difficult to navigate as companies return to physical workplaces with the pandemic still raging. Per Theodorou, “As workplaces reopen, there will likely be an uptick in the collection of biometric data as employers turn to symptom screening technologies that collect biometric data.” This could include, for instance, contactless thermometers and facial recognition scanning technologies used for contactless security access. The issue will thus continue to be the collection and storage of sensitive biometric data as employers return to work with the newfound priorities of social distancing and limited contact. The reality is that biometric data is still a relatively new concept, with its own specific set of issues and potential solutions. Personal privacy becomes ever harder to maintain in a digital world, with the use of biometric information often a necessity both for remote access and in-person return to work. Ultimately, the risks associated with the collection of biometric data remain largely undefined or misunderstood by employers. That lack of understanding has been exacerbated by a global pandemic necessitating a digital work migration.
IV. Possible Solutions to the Privacy Issues Raised by COVID-19 and Remote Workplaces
Illinois has provided a stellar blueprint for biometric data privacy in BIPA. However, other states have been slow to follow. As of November 2021, only a handful of other states have enacted legislation aimed at the protection of biometric data. Texas and Washington, like Illinois, have passed broad biometric privacy laws. Other states like Arizona and New York have adopted more tailored biometric privacy approaches, while others have enacted laws specifically aimed at facial recognition technology. There are also proposed bills awaiting legislative approval in many more states. Ultimately, implementing widespread legislation on a state-by-state basis will be a slow and drawn-out process, rendering countless Americans’ biometric data vulnerable. Rather than continue this state-based campaign to solidify biometric data privacy, citizens must turn to the federal government for a more comprehensive and consistent solution.
The primary roadblock to legitimate privacy in the biometric information space is the lack of a centralized federal initiative to address it. “Despite its value and sensitivity, the federal government currently has no comprehensive laws in place to protect the biometric data of U.S. citizens.” The privacy issues inherent in the popularization of biometric data in pandemic-era remote workplaces demand federal attention. A wide-ranging statute applicable in all states is the first step in properly addressing these issues. Congress should look to BIPA as a blueprint, for it remains the only state law passed to address biometric data privacy which includes a personal call to action. It is unique in that regard, especially considering it was passed in 2008, and consequently provides the most aggressive statutory response thus far to potential privacy concerns. Whether a federal act is feasible remains unclear. In August 2020, Senators Jeff Merkley and Bernie Sanders introduced the National Biometric Information Privacy Act of 2020, which suggests the imposition of nationwide requirements similar to those outlined in BIPA. The viability of such an Act is doubtful, as previous privacy legislation has been difficult to pass. However, it is a sign of movement in the right direction – toward increased protection of personal privacy in a pandemic which has made biometric data more relevant and potentially at-risk for improper management and manipulation.
Luke Shadley is a third-year law student at Northwestern Pritzker School of Law.
The development of AI systems has reached a point at which these systems can create and invent new products and processes just as humans can. There are several features of these AI systems that allow them to create and invent. For example, the AI systems imitate intelligent human behavior, as they can perceive data from outside and decide which actions to take to maximize their probability of success in achieving certain goals. The AI systems can also evolve and change based on new data and thus may produce results that the programmers or operators of the systems did not expect in their initial plans. They have created inventions in different industries, including the drug, design, aerospace, and electric engineering industries. NASA’s AI software has designed a new satellite antenna, and Koza’s AI system has designed new circuits. Those inventions would be entitled to patent protection if developed by humans. However, the United States Patent and Trademark Office (USPTO) has refused to assign the patent rights of these inventions to the AI systems.
The USTPO Denies Patent Rights to AI Systems
In a patent application that listed an AI system, DABUS, as the inventor, the USPTO refused to assign the patent right to DABUS and thus denied the patent application. DABUS invented an emergency warning light and a food container. The USPTO based its decision mainly upon a plain reading of the relevant statutes. 35 U.S.C § 115(a) states that “[a]n application for patent that is filed … shall include, or be amended to include, the name of the inventor for any invention claimed in the invention.” 35 U.S.C § 100(a) defines an “inventor” as “the individual, or if a joint invention, the individuals collectively who invented or discovered the subject matter of the invention.” 35 U.S.C § 115 consistently refers to inventors as natural persons, as it uses pronouns specific to natural persons, “himself” and “herself.” 35 U.S.C § 115 further states that the inventor must be a person who can execute an oath or declaration. The USPTO thus refused to extend its interpretation of “inventor” to an AI system, and it has stated that “interpreting ‘inventor’ broadly to encompass machines would contradict the plain reading of the patent statutes that refer to persons and individuals.
The Federal Circuit follows the same approach. In Beech Aircraft Corp. v. EDO Corp., the Federal Circuit held that “only natural persons can be ‘inventors.’” Therefore, in the current U.S. legal system, patent rights cannot be assigned for AI-generated inventions even though such inventions would be entitled to patent protection had they been created by humans.
Decisions regarding the patent protection for AI-generated inventions have spurred some disputes among academics. The creator of DABUS, Stephen Thaler, insisted that the inventions created by DABUS should be entitled to patent protection because DABUS is a system that can devise and develop new ideas, unlike some traditional AI systems that can only follow fixed plans. Stephen Thaler contends that DABUS has not been trained using data that is relevant to the invention it produced. Therefore, he claims, that DABUS independently recognized the novelty and usefulness of its instant inventions, entitling its invention patent protection. Thaler also raises an argument regarding the moral rights of inventions. Although current U.S. patent law may recognize Thaler as the inventor of these inventions, he emphasizes that recognizing him rather than DABUS as the inventor devalues the traditional human inventorship by crediting a human with work that they did not invent.
Some legal academics support the contentions of Stephen Thaler. For example, Professor Ryan Abbott agrees that AI systems should be recognized as inventors and points out that if in the future, using AI becomes the prime method of invention, the whole IP system will lose its effectiveness.
However, there are also objections to Thaler’s contentions. For example, AI policy analyst Hodan Omaar disagrees that AI systems should be granted inventor status because she believes that the patent system is for protecting an inventor’s economic rights, not their moral rights. She points out that the primary goal of patent law is to promote innovations, but Thaler’s proposed changes to patent law do little to do so. She argues that the value of protecting new inventions is for a patent owner rather than an inventor, which means that it makes no difference who creates the value. Thus, she concludes that listing DABUS as inventor makes no difference to the patent system. Omaar further argues that the proposed changes would introduce a legally unpunishable inventor that threatens human inventors, because the government cannot effectively hold AI systems, unlike individuals or corporations, directly accountable if they illegally infringe on the IP rights of others.
Patent Rights to AI Systems in Other Jurisdictions and Insights on U.S. Patent Law
Some foreign jurisdictions take the same stance as the United States. The UK Court of Appeal recently refused to grant patent protection to the inventions generated by DABUS because the Court held that patent law in the UK requires an inventor to be a natural person.
Despite failing to in the US and UK, Thaler succeeded in getting patent protections for the inventions created by DABUS in some other jurisdictions that allowed listing DABUS as the inventor. South Africa granted patent protection to a food container invention created by DABUS. This is the first patent for an AI-generated invention that names an AI system as the inventor. The decision may be partially explained by the recent policy landscape of South Africa, as its government wants to solve the country’s socio-economic issues by increasing innovation.
Thaler gained another success in Australia. While the decision in South Africa was made by a patent authority, the decision in Australia is the first decision of this type made by a court. The Commissioner of Patents in Australia rejected the patent application by Thaler, but the Federal Court of Australia then answered the key legal questions in favor of permitting AI inventors. Unlike patent law in the US, the Australian Patents Act does not define the term “inventor.” The Commissioner of Patents contended that the term “inventor” in the Act only refers to a natural person. However, Thaler successfully argued to the Court that the ordinary meaning of “inventor” is not limited to humans. The Court noted that there is no specific aspect of patent law in Australia that does not permit non-human inventors.
Examining the different decisions regarding the patent application of DABUS in different jurisdictions, we can see that the different outcomes may result from different policy landscapes and different patent law provisions in different jurisdictions.
For example, South Africa has a policy landscape where it wants to increase innovation to solve its socio-economic issues, while in the U.S., the government may not have the same policy goals related to patent law. Australia’s patent law does not limit an “inventor” to mean a natural person, while U.S. patent law specifically defines the word “inventor” to exclude non-human inventors in this definition. Thus, it is reasonable for U.S. patent law not to grant patent rights to AI-systems for AI-generated inventions, unless the legislature takes actions to broaden the definition of “inventor” to include non-human inventors.
The primary goal of the U.S. patent law is to promote innovation. If those who want to persuade the U.S. legislature to amend the current patent law to allow non-human inventors cannot demonstrate that such a change is in line with that primary goal, then it is unlikely that the legislature would support such a change. Whether granting patents to AI systems and allowing those systems to be inventors can promote innovation is likely to be an ongoing debate among academics.
Jason Chen is a third-year law student at Northwestern Pritzker School of Law.
If nothing else, Facebook’s recent announcement that it plans to change its name to “Meta” is a sign that the metaverse is coming and that our legal system must be prepared for it. As the metaverse, the concept of a virtual version of the physical world, gains increased popularity, individuals will engage in more transactions involving non-fungible tokens, or NFTs, to purchase the virtual items that will inhabit metaverse worlds. Accordingly, the United States will need more robust regulatory frameworks to deal with NFT transactions, especially in the gaming industry, where NFT use will likely rise significantly.
In most other areas of digital media and entertainment, NFTs are often associated with niche items, such as high-priced autographs and limited-edition collectibles. However, in the video gaming sector, existing consumer spending habits on rewards such as loot boxes, cosmetic items, and gameplay advantages provide fertile ground for explosive growth in NFT use. This article will explore the outlook for NFTs in gaming, why gaming NFT creators should consider the potential impact of financial regulations on their tokens, and how current U.S. financial regulations could apply to this ownership model.
A. Current State of Virtual Currencies and Items in Gaming
Gaming has long been the gateway for consumers to explore immersive digital experiences, thus explaining why virtual currencies and collectible items have such strong roots in this sector. Further, given the popularity of virtual currencies and collectibles in gaming, it is no surprise that cryptocurrencies and NFTs have similarly experienced success in this space.
NFTs, or non-fungible tokens, are unique digital assets that consumers may purchase with fiat currency or cryptocurrency. NFTs can be “minted” for and linked to almost any digital asset (e.g., video game items, music, social media posts), and even many physical assets. While NFTs are blockchain-based just like cryptocurrencies, the key difference between the two is that a NFT is not mutually interchangeable with any other NFT (i.e. they are non-fungible). So why are they so special? As digital experiences continue to move to the metaverse, NFTs will serve as a primary means for consumers to connect with companies, celebrities, and, eventually, each other.
In the simplest explanation, metaverse is the concept of a digital twin of the physical world, featuring fully interconnected spaces, digital ownership, virtual possessions, and extensive virtual economies. Mainstream media has already given significant coverage to metaverse activities that have appeared in popular games, such as concerts in Fortnite and weddings in Animal Crossing. However, more futuristic examples of how NFTs and metaverse could transform our daily lives exist in the Philippines with Axie Infinity and Decentraland, a blockchain-based virtual world.
In Axie Infinity, players breed, raise, battle, and trade digital animals called Axies. The game was launched in 2018, but it took off in popularity during the COVID-19 pandemic as many families used it to supplement their income or make several times their usual salary. To date, the game has generated $2.05 billion in sales. Meanwhile, plots of virtual land in Decentraland, a 3D virtual world where consumers may use the Etheruem blockchain to purchase virtual plots of lands as NFTs, are already selling for prices similar to those offered in the physical world. For example, in June 2021, a plot of land in the blockchain-based virtual world sold for $900,000.
The growth in popularity of Axie Infinity has already caught the eye of the Philippine Bureau of Internal Revenue, which has announced that Axie Infinity players must register to pay taxes. As financial regulation of NFTs looms, it will be imperative for U.S. gaming companies to consider how federal courts and the government will recognize the status of NFTs.
B. Financial Regulation and NFTs
As NFT transaction volume grows, there will undoubtedly be greater scrutiny over these transactions by financial regulators. While the current legal and regulatory environment does not easily accommodate virtual assets, there are a two primary ways NFTs may be regulated.
1. Securities Regulation
One of the most hotly discussed legal issues concerning NFTs involves whether these tokens should be recognized as securities. Under SEC v. W.J. Howey Co., a transaction is deemed an investment contract under the Securities Act where all of the following four factors are satisfied: (1) an investment of money; (2) in a common enterprise; (3) with a reasonable expectation of profits; (4) to be derived from the entrepreneurial or managerial efforts of others.
Intuitively, NFTs, in the form of virtual collectible items, don’t seem like traditional tradable securities as they are unique, non-fungible items. Indeed, they do not appear to demonstrate the type of “horizontal commonality” that federal courts have held to be necessary to satisfy the “common enterprise” aspect of the Howey test. “Horizontal commonality” is generally understood to involve the pooling of money or assets from multiple investors where the investors share in the profits and risk.
However, the Securities Exchange Commission has stated that it “does not require vertical or horizontal commonality per se, nor does it view a ‘common enterprise’ as a distinct element of the term ‘investment contract.’” Therefore, the fungibility aspect of the token alone may not preclude it from inclusion under securities regulation.
A more interesting inquiry might involve assessing whether the reasonable expectation of profits associated with an NFT is based on the “efforts of [others],” as outlined in Howey. In evaluating this element of the Howey test, the SEC considers whether a purchaser reasonably expects to rely on the efforts of active participants and whether those efforts are “undeniably significant” and “affect the failure or success of the enterprise.” Under this lens, how an NFT is offered and sold is critical to consider.
For example, if one mints (i.e., creates a NFT for) a piece of graphic art that sits and passively accumulates value, the failure or success of purchasing such a NFT would likely not be highly reliant on the activities of others. As the SEC has noted, price appreciation resulting solely from external market forces (such as general inflationary trends or the economy) impacting the supply and demand for an underlying asset generally is not considered ‘profit’ under the Howey test. Similarly, if a consumer purchases a digital pet, like those in Axie Infinity, that actively accumulates value through winning a series of battles, the success or failure of this digital pet would also not be highly reliant on the activities of others. However, this analysis becomes more complex when considering the recent increased interest in “fractional NFTs,” or “f-NFTs”, where an investor shares a partial interest in an NFT with others. Since these fractional interests are more accessible to a larger number of smaller investors, they may be more likely to drive market trading and, as such, be recognized as securities.
2. Federal Anti-Money Laundering Statutes
Under the Bank Secrecy Act, the Financial Crimes Enforcement Network, or “FinCEN,” is the U.S. Department of Treasury bureau that has the authority to regulate financial systems to fight money laundering. Although it has yet to comment directly on NFTs, FinCEN has released guidance suggesting that the movement of monetary value through virtual currencies could trigger money transmission regulations.
A critical factor determining whether the transfer of an NFT is a money transmission service will be whether FinCEN recognizes the NFT as “value that substitutes for currency.” If the NFT’s value may be substituted for currency then the transfer of such a NFT would likely trigger money transmission regulations. If players can purchase NFTs using a virtual currency that can cash out for fiat currency, then this transfer may be subject to FinCEN regulation. Alternatively, based on FinCEN’s recent guidance, even if NFTs are purchased with virtual currency that users cannot cash out for fiat currency, money transmission regulation may be triggered. Indeed, depending on how the gaming platform facilitates the transfer of in-game currency, regulatory risks may exist when users purchase third-party goods or make virtual marketplace transactions.
Earlier this year, Congress took a significant step towards making money transmission regulations more inclusive of NFT use cases when it passed the Anti-Money Laundering Act of 2020. Under the Act, art and antiquities dealers are now subject to the same anti-money laundering regulations that previously applied to financial institutions under the Bank Secrecy Act. This development will undoubtedly have a significant impact on the potential liability that gaming platforms can face as “dealers” of NFTs.
Conclusion
The United States is still a long way away from having laws that adequately regulate the creation, selling, and purchase of NFTs. However, NFT usage continues to increase rapidly. Nearly half of all U.S. adults are interested in participating in the NFT market, and gamers are 2.6x more likely to participate in the NFT market. As regulators move quickly to keep up with the pace of this market, firms will need to stay alert to ensure that they maintain regulatory compliance.
Rohun Reddy is a third-year JD-MBA student at Northwestern Pritzker School of Law and Kellogg School of Management.
When Meta’s services went down this past October, users were unable to access all of Meta’s applications, including Instagram, Messenger, and WhatsApp. This digital outage had physical consequences, as some Meta employees got locked out of their offices. The effects rippled outside of Meta’s own ecosystem, as some consumers soon discovered they were unable to log in to shop on select e-commerce websites, while others quickly found out that they could no longer access the accounts used to control their smart TVs or smart thermostats. Drawn by the ease of using Facebook accounts to log into websites, users had come to allow their Facebook account to act as a kind of digital identity. The outage, along with revelations from a fortuitously timed whistleblower, reminded users just how much individuals and governments depend on the “critical infrastructure” Facebook provides. Lawmakers in the U.S. have struggled with the question of how Meta should be regulated, or how its power should be reined in. One step towards mitigating Meta’s power would be to develop alternative digital Identity Management (“IdM”) systems.
The Legal Role of Identification
Technology has been used to verify identity for hundreds of years. Back in the third century B.C.E., fingerprints, recorded in wax, were used to authenticate written documents. For centuries, identification technology has allowed strangers to bridge a “trust gap” by authenticating and authorizing.[1]
In the present day, IdM systems have become a critical piece of technology for governments, allowing for the orderly provision of a range of services, like healthcare, voting, and education. IdM systems are also critical for the individual, because they allow a person to “prove[] one’s status as a person who can exercise rights and demand protection under the law.” The UN went so far as to describe an individual’s ability to prove a legal identity as a “fundamental and universal human right.”
Currently, there are over one billion people who live in the “identity gap” and cannot prove their legal identity. Put another way, one billion people lack a fundamental, universal human right. What makes this issue more pernicious is that the majority of individuals in the identity gap are women, children, stateless individuals and refugees. The lack or loss of legal identity credentials is correlated with increased risk for displacement, underage marriage, and child trafficking. Individuals living in the “identity gap” face significant barriers to receiving “basic social opportunities.”
Identity in Digital Age
The legal and social issues created by the “identity gap” are now evolving. In addition to the individuals who can’t prove their legal identity at all, there are over 3.4 billion people who have a legally recognized identification, but cannot use that identification in the digital world.
A 2017 European Commission Report found that an individual’s ability to have a digital identity “verg[es] on a human right.” The report then argued that one of the deep flaws of the internet is that there is no reliable, secure method to identify people online. The New York Times called this “one of biggest failures of the… internet.” Still, proving digital identity isn’t just a human rights issue; it’s also critical for economic development. A McKinsey report posited that a comprehensive digital IdM system would “unlock economic value equivalent to 3 to 13 percent of GDP in 2030.”
Digital IdM systems, however, are not without risk. These systems are often developed in conjunction with biometric databases, creating systems that are “ripe for exploitation and abuse.”
IdM Systems
Centralized
The most common IdM scheme is a “centralized” system; in a centralized IdM scheme, a single entity is responsible for issuing and maintaining the identification and corresponding information. In centralized IdM schemes, identity is often linked to a certain benefit or right. One popular example in the United States is the Social Security Number (“SSN”); SSNs are issued by the Social Security Administration, who then use that number to maintain information about what social security benefits an individual is eligible to receive. Having an SSN is linked to the right to participate in the social security system.
The centralized IdM schemes typically verify identity in one of two ways: via a physical and anti-forgery mechanism or a registry. These systems have proved remarkably resilient for a few reasons. They are easily stored for long periods of times and can be easily presented for many different kinds of purposes. Still, both ways have shortcomings, including function creep[2] and lack of security.
Identity systems that rely on anti-forgery mechanisms, like signatures, watermarks, or special designs, can also have security flaws. First, these documents require the checking party to validate every anti-forgery mechanism; this might require high levels of skill, time, or expertise. Additionally, once a physical identification is issued, the issuing party is generally unable to revoke or control the information. Finally, anti-forgery measures constantly need to be updated because parties have great incentives to create fake documents.
Another security shortcoming of centralized IdM systems is that they rely on registries to contain all their data. Registries are problematic because they have a single point of failure. If one registry is compromised, an entire verification system can be undone. For instance, if SSNs became public, the SSN would become worthless; the value is in the secrecy.
Equally significant is the possibility of function creep, which can happen when a user loses control of their identification. SSNs, for example, were designed for a single purpose: the provisioning of social security benefits. Now, SSNs serve as a ubiquitous government identifier that is “now used far beyond its original purpose.” This is problematic because SSNs contain “no authenticating information” and can easily be forged. It’s not just governments, however, that allow function creep in centralized IdM systems. This happens for privately managed identity systems as well, as the Facebook hack showed.
The Alternatives: Individualistic and Federated IdM Models
Another type of IdM system is an individualistic or “user-centric” system. The goal of these systems is to allow the user to have “full control of all the transactions involving [their] identity” by requiring a user’s explicit approval of how their identity data is released and shared. Unlike those in “centralized” schemes, these types of identification do not grant any inherent rights. Instead, they give individuals the ability to define, manage, and prove their own identity.
To date, technical hurdles have prevented the widespread adoption of these “user-centric” systems. Governments and private companies alike have proposed using blockchain to create IdM systems that allow individuals to access their own data “without the need of constant recourse to a third-party intermediary to validate such data or identity.” There is hope that blockchain can provide the technical support to create an “individualist” IdM system that is both secure and privacy-friendly. Still, these efforts are in their infancy.
The last major type of IdM system is a federated model. Federated IdM systems require a high degree of cooperation between identity providers and service providers; the benefit is single sign on (SSO) capabilities whereby a user can use their credentials from one site to access other sites. This is similar to the Facebook model of “identity.” The lynchpin of any such system, however, is who the “trusted external party,” who acts as the verifier, is. The risk is that these systems lack transparency, meaning users might not know how their data is used.
Conclusion
Using Facebook to verify identity online is quick and easy. Yet this system is inadequate. An individual’s ability to state, verify, and prove their digital identity will be “the key to survival,” particularly given how difficult it is to create trust in the digital space. Proving identity is a technical problem, but this technical problem is closely linked with an individual’s ability to act as a citizen, in person or online. Governments and corporations alike have recognized the importance of improved digital identity systems and have begun advocating for more standardized identity systems. Detractors of digital identification systems argue that an individual’s identity should not depend on the conferral of documents by a third party, and that relying on these types of documents is contrary to the idea that humans have inherent rights. They’ll then quickly point to examples of authoritarian governments who use identity tracking for evil purposes. These criticisms ignore the reality that proving identification is already an essential part of life and that many rights are only conferred when you have the proper identification. Further, these criticisms fail to recognize that superior identification systems will provide benefits that will accrue to society as a whole. They could be used to record vaccination status, fight identity fraud, or even to create taxation systems based on consumption.
Identification and identity are closely linked. As we transition towards even more digital services, taking steps to ensure that we have control over our digital identity will be more than a technology or privacy problem. Our ability to have and control our identity will continue to be a key driver of social and economic mobility.
[1] In this context, authentication is the ability to prove that a user is who they say they are, and an authorization function shows that the user has the rights to do what they’re asking to do.
[2] Function creep is when a piece of information or technology is used for more purposes than it was originally intended.
Henry Rittenberg is a 2nd year student in Northwestern’s JD-MBA program.
When a musician desires to record a cover version of a song (i.e., their own version of a song written or made famous by someone else), the process for obtaining the rights to do so is quite simple: they obtain a mechanical license—a compulsory license that can be obtained by paying the appropriate fee to the copyright holder or their representative—but only after the copyright holder has exercised their right of first publishing. And that’s all there is to it. The artist records their version of the song, releases it into the world, pays royalties to the copyright holder, and, so long as they have abided by all the aforementioned steps, they likely do not run into any issues relating to this process. This process is simple, but in a time where musicians liberally borrow material from others and the resulting songwriting credits read like novellas, it creates issues in a discrete subset of cases.
17 USC § 115(a)(2) provides that
A compulsory license includes the privilege of making a musical arrangement of the work to the extent necessary to conform it to the style or manner of interpretation of the performance involved, but the arrangement shall not change the basic melody or fundamental character of the work, and shall not be subject to protection as a derivative work under this title, except with the express consent of the copyright owner.
Under this provision, arrangements of musical works prepared under mechanical licenses do not receive copyright protection unless expressly granted by the copyright holder. For most musicians preparing recordings under this type of license, this is not a very concerning issue—they still retain a copyright in their sound recording, and they are likely to be the only users of their arrangement. But consider the following situation:
- An artist obtains a mechanical license in order to record a cover of a song.
- They write a new arrangement of the song, with additional musical ideas not present in the original arrangement of the song.
- They are unsuccessful in their attempts to gain the copyright owner’s consent for the arrangement to receive its own copyright protection.
- They record the song, using their new arrangement, and release the recording.
- Some time later, another artist writes a song which repurposes the aforementioned musical ideas present only in the arrangement prepared under the mechanical license.
What happens here? The arrangement is not provided copyright protection, but the new artist has to credit someone for the ideas that they repurposed in their new song. So, the songwriting credit for the portion borrowed goes to the original songwriters, even though they were not involved in writing the particular musical ideas.
Consider the following real-life example in order to understand the strange results that occur in these situations. In 1979, “And the Beat Goes On” was released by The Whispers. In 2002, “Reggae Beat Goes On,” a reggae cover of “And the Beat Goes On,” was released by Family Choice. Then in 2019, “How Long?”, a song containing elements of “Reggae Beat Goes On,” was released by Vampire Weekend.
“Reggae Beat Goes On” is a cover of “And the Beat Goes On,” and uses a very original arrangement in order to shift the genre from disco to reggae. The melody and lyrics remain the same and the chord structure is nearly the same as well, but the rest of the musical setting is different. “How Long?” takes elements from the musical setting of “Reggae Beat Goes On” and interpolates them in the new song. Namely, the guitar part from “Reggae Beat Goes On” is played on bass guitar in “How Long?” There are string parts brought over to “How Long?” from “Reggae Beat Goes On,” and the chords in both songs match as well.
Who are the credited writers for “How Long?”? There are five: Ezra Koenig, member of Vampire Weekend; Ariel Rechtshaid, producer of the record; and William Shelby, Stephen Shockley, and Leon F. Sylvers III, all writers of “And the Beat Goes On.” Bill Campbell, arranger of “Reggae Beat Goes On,” receives no songwriting credit for “How Long?” despite having written the external elements that are present in “How Long?”, while Shelby, Shockley, and Silvers receive credit despite not having written the material that was borrowed.
The result here seems absurd—the people receiving credit (and thus, also receiving royalties) did not actually write the borrowed material. However, the result is somehow in line with the purposes of and justifications for US copyright law. US copyright law is explicitly founded upon a utilitarian theory. Under a utilitarian theory, lawmakers have to decide which types of works to prioritize for copyright protection. And in reading 17 USC § 115(a)(2), it is clear that Congress chose not to give priority to arrangements of songs prepared under mechanical licenses. If US copyright law was founded upon a natural rights theory and all new works were automatically granted protection, this problem would likely not exist, but that is not the case—Congress must weigh the costs and benefits of expanding protection. Here, the absurd results justify Congress intervening.
One way to remedy this problem is to revise 17 USC § 115(a)(2) to automatically extend protection to arrangements prepared under mechanical licenses, even if the copyright owner has not expressly granted consent for the arrangement to receive copyright protection. If drafted carefully, the consequences would be minimal—the law would have to delineate which elements of the new arrangement are not eligible for protection, and in order to do that, the arranger would only have to look back to see what elements of the original song are afforded protection. Those protected elements would then be excluded from the protection afforded to the arrangement, while the rest of the elements, as well as the arrangement as a whole, would receive copyright protection. A revised version of 17 USC § 115(a)(2) could read as follows
A compulsory license includes the privilege of making a musical arrangement of the work to the extent necessary to conform it to the style or manner of interpretation of the performance involved, but the arrangement shall not change the basic melody or fundamental character of the work. All elements of the arrangement that are not subject to copyright protection under the original copyright shall be subject to protection as a derivative work under this title.
Congress made an explicit choice to not automatically extend copyright protections to arrangements prepared under mechanical licenses. In order to prevent absurd results that end with authors receiving credit for material they did not write and thus, receiving royalties for this work that they did not create, it would be prudent of Congress to revise 17 USC § 115(a)(2) to automatically provide copyright protection to arrangements of musical works prepared under mechanical licenses.
Michael Pranger is a 2nd year JD student at Northwestern Pritzker School of Law.
What’s The Issue?
It seems logical that the creator of a work would own the rights to that work. This general idea imports easily into some industries but creates problems in the music industry. The reality is that the main rights holder of a creative musical work is often not the musicians but collective management organizations (CMOs). After pouring countless hours, days, months, and years into perfecting a single music work or album, the musician often ends up not having total control over his or her work. The music industry is driven by smoke and mirrors where the distributors and records labels often do not disclose who owns the rights to which musical work. George Howard, co-founder of a digital music distributor called TuneCore and professor at Berklee College of Music, describes the music industry as one that lacks transparency. He explains that the music industry is built on asymmetry where the “under-educated, underrepresented, or under-experienced” musicians are deprived of their rights because they are often kept in the dark about their rights as creators.
As a result of the industry having only a few power players, profit is meek for musicians. Back in the day, musicians and their labels were able to get a somewhat steady source of income through physical album sales. However, with the prominence of online streaming, their main source of income has changed. The source of this issue seems to stem from how creators’ rights are tracked and managed.
A piece of music has two copyrights, one for the composition and one for the sound recording, and it is often difficult to keep track of both because the ownership of these rights are split amongst several songwriters and performers. The music industry does not have a way to keep track of these copyrights, and this is an issue especially when there are several individuals involved in creating a single musical work. With the development of digital ledger technology and its influence in various industries, it could be time that this development makes its way into the music industry and provide a solution to compensate musicians for their lost profits.
Blockchains: the solution?
Lately, blockchain technology has been at the forefront of conversations. For example, the variation in Bitcoin’s pricing has been a hot topic. Blockchain technology seems like a mouthful, but it is simply a “database maintained by a distributed network of computers.” Blockchains allow information to be recorded, distributed across decentralized ledgers, and stored in a network that is secure against outside tampering.
With the advancement of online music streaming, and entertainment going digital, blockchain seems like the perfect tool to be used in this industry. Since the issue of weakened profits seems to stem from disorganized tracking and monitoring of creators, blockchain technology could be utilized to improve the systems used for licensing and royalty payments. A blockchain ledger would allow a third party to track the process of a creative work and be an accessible way of managing intellectual property rights of these creative works. By tracking and monitoring their works, musicians could potentially gain back their profits, or at least recuperate some of their losses.
In 1998, there were several companies that came together to create a centralized database to organize copyrights for copyright owners so that royalty payments would be made in an orderly fashion. This effort was called the Secure Digital Music Initiative (SDMIT) and its purpose was to “create an open framework for sharing encrypting music by not only respecting copyrights, but also allowing the use of them in unprotected formats.” Unfortunately, this initiative failed to provide a universal standard for encrypting music.
The latest venture was the Global Repertoire Database (GRD) which aimed to “create a singular, compiled, and authoritative ledger of ownership and control of musical works around the world.” This was a very ambitious move and required two rounds of financing which consisted of the initial startup funds and the funds to cover the budgeting for the year. Although there were significant contributions to this mission, some collection societies, such as the American Society of Composers, Authors and Publishers (ASCAP), started to pull out of the fund due to GRD’s failure and debt that it accumulated.
Even though this venture failed to provide a centralized database that could resolve royalty and licensing issues, there is now a growing consensus in the music industry for a global, digital database that properly, and efficiently, manages copyright ownership information. The next venture could utilize blockchain technology because of the advantages for storage, tracking, and security that it offers. In addition, not only could blockchain provide a centralized database so that music content information is accurately organized, it could provide a way to close the gap between creators and consumers and dispose of intermediaries. This would allow for a more seamless experience and transparency for the consumer and allow the creators to have more control over their works. Further, this ledger would allow these creators to upload all of their musical work elements, such as the composition, lyrics, cover art, video performances and licensing information, to a single, uniform database. This information would be available globally in an easily verified peer-to-peer system.
On the other hand, since blockchains are tamper-resistant, the data could not be “changed or deleted without affecting the entire system” even with a central authority. This means that if someone decides to delete a file from the system, such a deletion will disrupt the whole chain. There could also be issues with implementing such a large network of systems, or computers, due to the sheer amount of music that is globally available. Additionally, to identify each registered work, the right holders have to upload digital copies of their works which would require an extensive amount of storage and computational power to save entire songs.
Nevertheless, blockchain could provide the base for implementing a centralized database using a network of systems, or computers, in order to organize royalty payments for these musicians. Proponents contend that, with the help of Congress, this could be made possible. Congress recently introduced Bill HR 3350, Transparency in Music Licensing and Ownership Act. This act, if passed, will require musicians to register their songs in a federal database or else forfeit the ability to enforce their copyright, which would prevent them from collecting their royalties for those works. Although this might seem like an ultimatum, this proposed Act would provide the best way of changing how the music industry stores its information to provide an efficient way to distribute royalties and licensing payments to these artists.
Conclusion
People are split in their opinions about blockchain technology in the music industry. There are some who see this as a more accurate way of managing “consumer content ownership in the digital domain.” Others do not see this as a viable plan due to its lack of scalability to compensate for the vast amount of musical works. Even with the development of the music industry into the digital field, the goal is always to protect the artists’ works. Plan [B]lockchain ledger may not completely solve the royalty problem in the music industry, but it can provide a starting point in creating a more robust metadata database and, in combination with legislative change, the musical works could remain in the hands of their respectable owners.
Jenny Kim is a second-year law student at Northwestern Pritzker School of Law.
Introduction
Throughout the past two years, AI-powered stem-splitting services have emerged online, allowing users to upload any audio file and access extracted, downloadable audio stems. A “stem” is an audio file that contains a mixture of a song’s similarly situated musical components. For example, if one records a mix of twenty harmonized vocal tracks, that recording constitutes a vocal stem. Stems’ primary purpose is to ease integrating or transferring their contents into either a larger project or a different work. Traditionally, only producers or engineers created and accessed stems. Even when stem sharing became commonplace, it was only for other industry insiders or those with licenses. But AI stem-splitting technology has transformed stem access. For the first time, anyone with internet access can obtain a stem through stem extraction software, which will likely push music production’s creative envelope into new realms. One inevitable consequence, however, is the question of copyright protection over stems extracted from copyrighted works.
Section 102 of Title 17 extends copyright protection not only over the stems’ original copyrighted audio source but also over that source’s components, such as the stems. Any modification of that work, such as extracting a stem and using it elsewhere, likely qualifies as a “derivative work” under Section 103. Importantly, Section 106 allows only copyright owners to authorize making derivative works. In light of this regime, what flexibility, if any, do artists have in using AI-extracted, copyrighted stems? Three considerations shed light on an answer: fair use, de minimis use, and the use of content recognition software coupled with licensing.
Fair Use
Codified under Section 107, the fair use defense provides a possible safeguard for would-be infringers. To establish this affirmative defense, a court would need to find the statute’s four factors sufficiently weigh toward “fair use.” Unfortunately, courts reach incongruous interpretations of what permissible fair use includes, rendering the defense a muddled construct for many artists. Squaring the four factors with stem usage, however, may offer guidance.
- The purpose and character of the use, including whether such use is of a commercial nature or is for nonprofit education purposes
In the seminal music fair use case, Campbell v. Acuff-Rose Music, Inc., the Supreme Court emphasized that this first factor will likely weigh toward fair use when the work is “transformative.” The Court went so far as to note “the more transformative the new work, the less will be the significance of other factors . . . .” Thus, an artist fearing infringement should strive toward transforming the copyrighted material into something distinct, used for noncommercial purposes. In the absence of a bright-line rule from the Court, however, artists will still need to use reasonable judgment about what types of stem usage is “distinct.” For example, suppose Artist A extracts a strings stem from a copyrighted work and only uses two seconds of it within another work that comprises numerous other instruments and melodies. Meanwhile, Artist B extracts the same strings stem; however, Artist B uses the entire strings melody within their work and only adds percussion and minor counter-melodies. Artist A would likely be in a more favorable legal position than Artist B given A’s efforts to materially transform the copyrighted audio.
The commercial nature of copyrighted stem usage is also unclear. An artist may choose to work with stems for solely experimental purposes. For example, an artist who shares their work via Soundcloud or YouTube does not expect another person to use those platforms to directly purchase the work. With stems’ increasing public accessibility, many will simply want to experiment with a music tool that, until recently, has largely remained a foreign concept. If this issue reaches a court, the court would need to conduct an analysis set against the landscape of such heightened accessibility. An increase in this noncommercial, creative use may offer hope to artists in the future, but it is too soon to tell.
- The nature of the copyrighted work
The second factor favors artists borrowing from copyrighted works with lower creative value. Unfortunately, music is typically found to be one of the most creative forms of copyrighted work. For example, a district court in UMG Recordings, Inc. v. MP3.Com, Inc. analyzing this second factor noted that the disputed material—copyrighted musical works—was “close[] to the core of intended copyright protection” and “far removed from the more factual or descriptive work more amenable to ‘fair use.’”
Though courts’ future inquiries into stem usage may differ from previous analyses of sample usage, the inquiry will likely change very little for this factor. Although a stem could potentially represent only a minute portion of the song, this factor’s inquiry focuses on the source of the stem, rather than the stem itself. Consequently, rarely will this factor work to a potentially infringing artist’s benefit, even if their stem usage is quite minor.
- The amount and substantiality of the portion used in relation to the copyrighted work as a whole
The third factor, however, may offer hope for such minor stem usage. Courts will undoubtedly reach differing interpretations about how minimal the copyrighted portion’s “amount” and “substantiality” must be for this factor to weigh toward fair use. A court will need to weigh numerous variables and how they intersect. For example, is an artist using a thirty-second loop of a vocal stem or a five-second loop? Does that vocal stem include the chorus of a song? What about any distinct lyrics? Just minor humming? These considerations are not entirely novel. Artists purporting to use copyrighted samples have long been able to argue—with little success—that their samples’ amount and substance pass muster under this factor. Yet, stems are not samples; in fact, they typically represent a considerably smaller portion of a work. Given just how recent and novel their public accessibility is, it remains unclear whether a court would treat stem use any differently under this factor than it has treated instances of sample use. Carefully using a minor portion of a vestigial stem to avoid a work’s core substance, therefore, could potentially facilitate a favorable outcome.
- The effect of the use upon the potential market for or value of the copyrighted work
The fourth and final factor of fair use is “[u]ndoubtedly the single most important element.” This factor examines both the infringement’s effect on the potential market and “whether unrestricted and widespread conduct of the sort engaged in by the defendant . . . would result in a substantially adverse impact on the potential market for the original.”
In the sampling realm, this factor has tipped the scales before. For example, in Estate of Smith v. Cash Money Records, Inc., a district court found fair use when the defendants inserted a thirty-five-second “spoken-word criticism of non-jazz music” into a hip-hop track. In its analysis of this fourth factor, the court emphasized that “there [was] no evidence” that pointed to overlapping markets between the spoken jazz track and the hip-hop track. The court, noting this factor’s high probative value, then weighed this factor in the defendants’ favor.
In the stem realm, the novel nature of widespread public use means courts will need to determine both whether this factor should remain highly probative and how much deference to give stem users in analyzing market overlap. After all, an artist who incorporates a stem into a work intended for a twenty-five-person YouTube following likely affects the original work’s market differently than an artist who disseminates that work to millions of followers. This factor’s outcome will also rely on the stem’s source. Similar to sampling, if an artist uses a stem in a drastically different arena than the one for which the stem was created, this factor will weigh more toward fair use.
For example, suppose Artist A locates an insurance advertisement jingle. Artist A then extracts a stem from that advertisement audio and uses the stem in a new hip-hop track. The advertisement’s potential market is likely different from the hip-hop track’s potential market. Artist A’s work would likely have little impact, if any, on the advertisement’s market. Artist B, meanwhile, creates a hip-hop track but uses a stem from another hip-hop song produced twenty-five years ago. Though Artist B may believe the stem from the older hip-hop track no longer caters to the same hip-hop market to which Artist B is targeting, a court may be more inclined to find a material impact on the older track’s market: it would provide another way in which music listeners, particularly hip-hop listeners, could hear that older track. Nonetheless, it would remain up for a court to decide.
De Minimis Use
Artists might also be able to use extracted, copyrighted stems if such use is de minimis. The Ninth Circuit in Newton v. Diamond held de minimis use—“when the average audience would not recognize the appropriation”—is permissible. Yet, following the Newton decision, the Sixth Circuit in Bridgeport Music, Inc. v. Dimension Films foreclosed the possibility of de minimis copying. Similar to fair use analysis, it is difficult for an artist to determine whether the use of a stem in their work is de minimis under this standard.
Thus, an artist who loops only a small, relatively generic-sounding portion of a stem may find additional legal protection. But they might not. If they are in a jurisdiction that does not recognize de minimis use, or they use a stem in a way that extends beyond what a court considers de minimis in a de minimis jurisdiction, this avenue will be unavailable.
Content Recognition Software
Beyond legal defenses, a newer scheme of licensing deals coupled with content recognition software may offer protection for stem usage. For example, if a user on the content platform TikTok uploads content with copyrighted audio, TikTok’s content recognition software recognizes the audio, then pays the appropriate royalties to the audio’s copyright holder through preexisting licensing deals. Yet, because schemes like TikTok’s and stem usage are both relatively new, it remains unclear whether artists could find the same protection through individual stem use. Indeed, if an artist uses only a small part of a single stem, it may very well be impossible to detect the stem’s source; however, emerging technology may change this soon. Further, these licensing deals restrict such artists to sharing work only on particular platforms—notably, neither Soundcloud nor YouTube. Ultimately, this protection carries promising potential for expanded, authorized stem use. But perhaps not quite yet.
Matthew Danaher is a second-year law student at Northwestern Pritzker School of Law.
What are Copyright Bots?
Digital media handles like Instagram, YouTube, and Tik Tok are now the platforms of choice for creators, new and old, to showcase their work. The accessibility of these platforms opens an untapped market of creativity, allowing for anyone with a smartphone to disseminate their work. With great freedom, though, the potential for copyright infringement skyrockets.
This is where copyright bots come in. Also known as content recognition software, copyright bots are automated systems programmed into digital media platforms that compare uploaded content against an archive of copyrighted content to recognize similar works. The copyright owners, or the platforms utilizing copyright bots, can then examine the similar works to determine whether the work is an actual copy, whether the copy is licensed, and whether legal action to remove the work is merited. Some bots can even handle the enforcement of the copyright by sending out notices and handling appeals.
The Digital Millennium Copyright Act (DMCA) of 1998 is one explanation for the popular use of copyright bots. Under the Act, online service providers can be held liable for direct infringements of copyrighted work made by its users that they are aware of, regardless of whether they are responsible or receive any kind of financial benefit from the infringement. Fortunately, the safe harbors provision of the DMCA provides immunity from secondary infringement liability as long as the online provider swiftly removes and disables access to the infringing material. This incentivizes providers to use automated systems capable of acting expeditiously.
Another explanation for the use of copyright bots is necessity. There is simply too much new content being uploaded for humans to manually search on their own. To put it in perspective, 720,000 hours of video are uploaded to YouTube every day. If human reviewers are equivalent to a guard dog, then copyright bots are an entire army, able to identify, analyze, and compare uploaded content at a rate that is not viable for humans.
The Benefits and Risks of Copyright Bots
Copyright bots provide substantial benefits to copyright owners and digital media platforms. Without bots, it would take a lifetime for copyright owners to police a fraction of YouTube’s content alone. Humans’ limitation in identifying similar works results in thousands, even millions, of works neglected under the radar.
Copyright bots, on the other hand, provide a copyright owner with an all-inclusive overview of similar works because they can effortlessly sift through content at a relatively instant speed. They can also enforce a copyright owners rights without any oversight. Consequently, this automated method identifies all matches, allowing copyright owners to comprehensively enforce their rights against all, instead of just a fraction, of unauthorized uses.
Digital media platforms also benefit significantly from the use of copyright bots. According to YouTube, over 98% of copyright issues on the platform are handled by their content recognition software. With the eminent risk of liability under the DMCA, it’s no wonder why YouTube and other platforms use overzealous copyright bots.
Nevertheless, copyright bots pose several risks. First, copyright bots are far from perfect and tend to produce false positives. The automated systems often flag content that uses a de minimis amount of copyrighted material, or material that is in the public domain. In particular, bots do not have an ear for classical music, which exists as a frequently revisited collection of public-domain works that are distinguishable through slight variations in performance.
Copyright bots’ tendency to produce false positives disproportionately favors the interests of digital media platforms and copyright owners. Both groups have an incentive to remove as many close matches as possible, even when they are false positives that don’t constitute infringement. This is especially true for digital media platforms that are motivated to rigorously comply with the DMCA’s notice-and-takedown process to shield themselves from liability. Overall, there is little to no deterrent for digital media platforms and copyright owners to eliminate any and all content identified by the bots.
On the other hand, the odds are against content creators when they appeal a takedown notice. If they lose on the appeal, they risk having their digital media accounts blocked and being forced to pay a high licensing fee or settlement payment. Content creators fear receiving a takedown notice every time they post new content. Doug Walker, a popular YouTube host, said that his fear of takedowns when administered by a bot has made him never feel safe posting a video, even though “the law states that [he] should be safe” posting his videos. As a result, many content creators, like Walker, choose to censor themselves instead of gambling on an appeal.

Second, copyright law is intended to allow for flexibility and discretion in the analysis of whether a new work infringes a protected work. Bots, however, are unable to decipher the difference between fair uses of a copyrighted work—works that are a parody, intended for educational purposes, or have been transformed—from works that are infringing.
For example, Richard Prince’s series of paintings called “Canal Zone,” in which Prince added an animated guitar and eyes to an existing photographic work of a Rastafarian man, likely would be signaled and shot down by copyright bots. But the court in Cariou v. Prince found that “all but five of Prince’s works do make fair use of Cariou’s copyrighted photographs.”
Bots’ limited ability to recognize the limitations on copyright law risks granting monopolies to the original owners, which is something copyright law is intended to prevent.
Copyright Bots’ Impact on the Policy Goals of Copyright Law
In addition to the short-term effect on content creators, copyright bots’ deficiencies ultimately harm copyright law’s policy goals. Copyright law stems from Article 1 Section 8 clause 8 of the Constitution: “Congress shall have power to… promote the progress of science and useful arts, by securing for limited times to authors and inventors the exclusive right to their respective writings and discoveries…” Under the United States’ utilitarian perspective, the exclusive rights of reproduction, adaptation, publication, performance, and display afforded to copyright owners is intended to foster creativity and innovation to benefit the public. What copyright law does not grant, however, is a monopoly over original works with a modicum of creativity.
Copyright bots do a good job of protecting owners’ rights across a broader range, and they help keep digital media platforms within the safe harbors of the DMCA. However, overreliance on copyright bots risks granting monopolies to copyright owners and turns a blind eye to the intended limitations on copyright law. This is especially true when the bots themselves are also in charge of enforcement.
Moreover, the bots’ rigorous administration of owners’ rights fails to acknowledge the lawfulness of works that supersede the objects of original creation or add something new with further purpose or different character. Transforming a copyrighted work or using it for educational purposes benefits society and achieves copyright law’s policy goals.
If digital media platforms continue to take a back seat while bots drive enforcement, copyright law in the online world will discourage creativity and innovation. Ultimately, this will halt the advancement of science and the useful arts. Even worse, creators may start focusing on ways to avoid copyright bot detection instead of spending time adding value, information, or new aesthetics to copyrighted material, thereby failing to further progress and protect owners’ rights.
Moving Forward
Copyright law’s design leaves room for discretion to balance the tension between copyright owners’ rights and creators’ liberty. Digital media platforms should embrace the permitted use of copyrighted material to maintain the peace between copyright owners and creators instead of unleashing their bot armies on the slightest hint of a potential infringement. As human oversight dwindles, and the use of bots rises, creators will be forced to learn the bots’ algorithm to avoid attacks instead of enjoying and capitalizing on their freedom under the fair use doctrine.
The easiest solution would be to eliminate copyright bots entirely. However, bots are necessary considering the sheer volume of new content uploaded every minute. Nonetheless, they need revision to be more skeptical of works that are similar to or contain copied material. There also needs to be human oversight, especially during the enforcement stage, until copyright bots can differentiate between infringing works and fair uses. It’s time for copyright bots to receive a much-needed tune up before they rewire content creators and deprive the online world of their artistry.
On July 1, 2021, the original source code for the World Wide Web sold for $5.4 million at a Sotheby’s auction. This was not the actual source code, which is open source and freely available in the public domain, but rather a non-fungible token (NFT) version of the source code. NFTs, a new block chain based asset, have been making waves as everyone — from artists, sports leagues, to exiled whistleblowers and institutional investors — looks to participate in the craze by creating and selling digital assets for millions of dollars. (See also) So, what are NFTs, and what property rights and liabilities do buyers take on with their purchases?
What are Non-Fungible Tokens?
Non-fungible tokens, or NFTs, are unique digital assets stored on blockchain and used to create authenticated digital ownership of a scarce asset. The concept was first introduced by Vitalik Buterin, creator of the fungible crypto currency Ethereum, in December 2012 with “Colored Coins.”
An NFT uses “smart contracts,” which are open-sourced blockchain protocols outlining specific terms and conditions for the transfer of digital ownership. The smart contract is then permanently “minted,” or stored onto a blockchain token (most commonly Ethereum) creating an immutable record of the token’s history, from its creation all the way to its most recent sale. The secure digital storage of ownership records is one of the chief benefits of NFTs as a vehicle for storing wealth, especially compared with similar markets, like art, which are often plagued with authentication problems.
In 2017, the potential for digital assets as a means to store and create wealth was first initiated when CryptoPunks launched the world’s first marketplace for NFT digital art on the Ethereum blockchain. The project’s creators distributed 10,000 different claimable cartoon characters to entice market participants, and the characters were quickly claimed and subsequently traded in a freely formed secondary market.
State of the Market Today
Today, the NFT market is exploding. For example, on August 28, 2021, just four years after launch, CryptoPunks crossed $1 billion in all time sales. Much of this growth has occurred over the past twelve months. During 2020, NFT sales are estimated to have totaled a mere $94.7 million; however, for 2021 NFT sales have sky rocketed all the way to $24.9 billion. Much of this growth occurred in the second half of the year with sales volume growing from a combined $2.1 billion during Q1 and Q2 to a combined $22.3 billion during Q3 and Q4. Despite current volatile equity markets, NFTs continue to remain popular during 2022, with OpenSea, the largest NFT marketplace, announcing a record $5 Billion in transaction volume for the month of January.
Much of the NFT growth has been attributed to increased demand and acceptance for cryptocurrencies, coupled with an increased participation in public consumer trading during the COVID-19 pandemic. The explosive growth has drawn increased media attention, which has further fueled its virtuous cycle. Today, blue-chip companies like Coca-Cola are issuing their own NFTs, while institutional investors and fund advisors like Andressen Horowitz are investing heavily in the NFT marketplace, demonstrating confidence in its continued growth. Accordingly, this formerly fringe product has come under increased legal and regulatory scrutiny.
The scope of transferred property rights with NFTs
The rights acquired by an NFT purchaser vary widely based on how and where the NFT was acquired. In most cases an NFT holder, similar to a purchaser of a physical collectible, is purchasing a non-exclusive license to the underlying intellectual property rights of the asset for a non-commercial purpose. However, unlike a physical collectible, a digital NFT is easily and cheaply created, reproduced, or downloaded. A crucial distinction is that an NFT holder is merely acquiring the rights to the blockchain token imprinted with the intellectual property, and not the underlying intellectual property itself. Furthermore, for many NFTs the blockchain is unable to store the actual underlying digital asset, so what is actually being bought is an imprinted link to the asset. As a result, the underlying copyright only transfers if the copyright’s owner assents to such transfer in writing alongside the transfer of the digital asset.
The totality of the rights associated with the token are defined by the smart contract. Thus, there is a huge importance on the drafting of the smart contract coded into the token during an NFT transaction, which is an element not evinced during a physical collectible sale.
Smart contracts are the coded instructions of the NFT defining the scope and limitations of use. Depending on where the NFT is acquired the license agreement can vary immensely. The NBA Top Shot platform is an example of a proprietary marketplace, meaning the NFTs are created by a single market operator who does not allow third party transactions. For their platform, Top Shot has promulgated an internal standard NFT license agreement. These kinds of agreements stipulate that the buyer receives, “(i) a personal license to use and display the art associated with the NFT, as well as (ii) a commercial license to make merchandise that displays that art associated with the NFT, a license subject to a $100,000 gross revenue per year limit.” Given the market operator is minting all listed products, this concentrates even more control in the market operator and typically transfers the fewest rights to the subsequent owner, as evidenced by Top Shop limiting the ability of future owners to commercialize their purchase.
On the other end of the spectrum is OpenSea, an example of an “open” marketplace that allows anyone to mint and sell NFTs and enables customizable licenses. For example, an NFT of a tungsten cube sold for $200,000 and included the right to touch a physical one-ton tungsten cube stored at Midwest Tungsten Service headquarters once per year. This market offers financial freedom, but also features high risk of fraud due to ease of access, lack of market oversight, and difficulty in tracing actual wallet ownership.
In the middle are curated marketplaces, which require artists to apply to have their items listed by the market operator; however, unlike proprietary marketplaces, any creator can apply to have their NFT listed so long as the NFT conforms with the market operator’s regulations. Approval generally requires the NFT seller to abide by the market’s standard license agreement, similar to the proprietary market.
Regardless of who is dictating the terms, NFT license agreements cover a variety of issues tied to which property rights are being transferred. Typically, this includes many common terms and conditions such as indemnification clauses, buyer and seller rights, and definitions for various duties and obligations amongst others. However, the intrinsic qualities of an NFT also necessitate some atypical clauses such as ownership of platform IP, digital wallet verification, and outlining the commercialization or transfer rights. The most important and heavily scrutinized term of an agreement though is how the agreement handles the ownership of the copyright connected to the token. Thus, understanding the terms contained in these agreements is essential to evaluating and participating in this fast growing and evolving digital marketplace.
The potential for copyright infringement and liability for NFTs
While blockchain can authenticate the transactions, blockchain is unable to inform the buyer if the seller has rights to underlying copyrighted work or is merely selling someone else’s copyrighted work. This is important because section 504 of the Copyright Act holds even an innocent actor who unknowingly violated somebody else’s copyright automatically liable for both actual and statutory infringement damages. Recently, an NFT of Whales produced by a 12 year old programmer was sold for thousands of dollars, only for the images to later be discovered to have been copied directly from another project. Assuming the use constituted infringement (the issue has not yet been litigated), the buyer at a minimum is liable to return the NFT to its rightful owner and handover any profits. Furthermore, if the buyer knew there was a potential infringement and still sold the NFT, the statutory liability could be over a million dollars.
Conclusion
NFT case law is still being developed, with the first cases just now working their way through the legal system. As the market continues to grow, more regulatory agencies, including the SEC, are taking a closer look at security status and potential acts of fraud. However, until the regulatory status is cleared NFTs exist in a caveat emptor market. The onus is on the purchaser to verify the terms of the license agreement they are acquiring, the status of the seller, and the underlying intellectual property. While blockchain makes the verification and authentication process easier, it still has gaps creating additional liability, especially for copyright infringement.