Author: adefranco
The Development of Artificial Intelligence
Today, Artificial Intelligence (AI) has developed into deep learning. Deep learning is the ability of an AI system not only to learn but also to independently make decisions without human intervention. With the development of deep learning, services that automatically compose music or draw a picture are appearing. For example, Google’s experimental “Auto Draw” tool uses deep learning algorithms to suggest complete drawings as users roughly sketch out their ideas. With the development of these types of AI services, there are copyright issues relating to both the inputs and outputs of such systems.
These services are still in the early stages, but as these services develop, they have the potential to produce results of commercial value. Therefore, their development may produce copyright issues. This post will (i) explain some copyright issues that may arise in relation to such deep learning services in two main categories and (ii) introduce the current situations in the U.S., South Korea, and Japan.
Deep Learning and Copyright
There are two major copyright issues related to services using deep learning. The first issue concerns the use of third-party data that is necessary for the learning process of a deep learning system. In general, copyright law requires permission from the rights holders for all such data. However, in many cases, it is practically impossible to obtain consent for all of the data that deep learning services use.
The second issue relates to the rights of AI-generated works. If contracts or legal documents created by AI have commercial value, then who owns the copyright of those works? In such situations, there is the possibility of a dispute between the AI service provider and the user using that service over the rights to any profit generated.
The current state of the law in the U.S., South Korea and Japan
A. United States
The first issue, permissive use, is whether using training data constitute unauthorized reproduction, thereby giving rise to copyright infringement liability. Circuit courts are divided on this issue.[i] However, even if infringement occurs during machine learning, training AI with copyrighted works would likely be excused by the ‘fair use’ doctrine.[ii] For example, in Authors Guild v. Google, Inc.[iii], Google had scanned digital copies of books and established a publicly available search function. The plaintiffs alleged that this constituted infringement of copyrights. The Second Circuit held that Google’s works were non-infringing fair uses because the purpose of the copying was highly transformative, the public display of text was limited, and the revelations did not provide a significant market substitute for the protected aspects of the originals. The court also said that a profit motivation in and of itself did not justify denial of fair use.
On the ownership issue, it is not clear whether the U.S. Copyright Act itself explicitly requires the author of a creative work to be human. However, the U.S. Copyright Office, by publishing “The Compendium II of Copyright Practices,” went beyond the statutory text in requiring that an author be human in order for the work to be eligible for copyright protection.[iv] And in Naruto v. Slater[v], Naruto, a crested macaque monkey, took several self-portrait photographs with photographer’s unattended camera. The Ninth Circuit dismissed the copyright claims brought by Naruto’s representative PETA.
B. South Korea
Currently, regarding permissive use, there are no regulations relating to AI learning data in the Copyright Act of South Korea. Therefore, when copyright-protected materials are used as AI learning data under the current law, that use may conceivably be judged as copyright infringement. However, Article 35-3(1) of South Korean law states that “… where a person does not unreasonably prejudice an author’s legitimate interest without conflicting with the normal exploitation of works, he/she may use such works.” In other words, the fair use doctrine is also possible under South Korean law, and there is a possibility that this provision will apply to AI learning.
Thus, with no legal provisions in place and with no relevant precedent cases, this legal uncertainty acts as an obstacle to the use of data in AI learning in South Korea. However, the South Korean Ministry of Culture, Sports and Tourism is working on a revision of the Copyright Act to include a clause that does not require consent of the copyright holder to the extent that the material is used for AI learning and big data analyses. The revised Act was proposed in Korean National Assembly on January 15th 2021, and the procedure is currently underway.
Regarding the ownership issue, the Copyright Act of South Korea defines the term “work” to mean “a creative production that expresses human thoughts and emotions” in Article 2(1), and “author” to mean “a person who creates a ‘work’” in Article 2(2). As such, unless the current law is amended, only humans can be the authors of creative endeavors. Therefore, AI-generated works are not protected by the current law.
However, South Korea may also see progress on this front. The Presidential Council on Intellectual Property formed the AI-Intellectual Property Special Expert Committee in June of 2020 to establish a pan-government AI policy. This committee will discuss a variety of policy issues, such as 1) whether AI should be recognized as an author, 2) whether the works created by AI should be protected to the same level as those by humans, and 3) who owns the work created by AI.
C. Japan
Japan has already solved the problem of permissive use through legislation. Japan revised related regulations through the revision of the Copyright Act on May 25, 2018. According to Article 30-4 of the new Copyright Act, it is permissible to exploit a work as necessary if it is used in data analysis. As a result, there are no restrictions on the subject, purpose, and method of data analysis, and there is no obligation to compensate the copyright holder. It is now also permitted to provide learning data in cooperation with multiple corporations.
Regarding ownership, under Japan’s Copyright Act Article 2(1), a copyright-protected work is defined as a creation expressing “human thoughts and emotions.” Thus, it appears difficult for AI to become the author of its own creations under the current law. To address this, the “Intellectual Property Strategy Headquarters” of the Prime Minister’s Office has suggested specific policies for AI copyright policy in its “Intellectual Property Promotion Plan 2016.” Specifically, this plan says that in order to promote AI creation, incentives to those involved in AI creation must be guaranteed. Thus, it is necessary to recognize the copyright of AI creations as well. However, the policy also stated that granting IP protection to all AI-created works may be subject to excessive protection. Thus, it is necessary to limit the content and scope of recognition of rights in consideration of the need for such protection.
Conclusions and Final Thoughts
Regarding the permissive use issue, unlike the U.S. and Japan, South Korea still has legal uncertainty. In South Korea, more specific legal provisions are required for using copyright-protected works as learning data for AI as a fair use. If the Copyright Act is amended, this problem can be resolved. Thus, it is necessary to watch for future progress.
In terms of the ownership issue, each of these countries currently has a problem in that the author of copyright must be human. Therefore, it is necessary to amend the copyright law for attribution of the rights of AI-generated works. However, a more detailed and careful discussion on who precisely will hold that copyright, is still needed.
Seung Hoon Park is a third-year law student at Northwestern Pritzker School of Law.
[i] Jessica L. Gillotte, COPYRIGHT INFRINGEMENT IN AI-GENERATED ARTWORKS, 53 U.C. Davis L. Rev. 2655, 2674-76 (2020).
[ii] Id. at 2659.
[iii] Authors Guild v. Google, Inc., 804 F.3d 202 (2d Cir. 2015).
[iv] Shlomit Yanisky-Ravid, Generating Rembrandt: Artificial Intelligence, Copyright, and Accountability in the 3A Era — The Human-Like Authors Are Already Here — A New Model, 2017 MICH. ST. L. REV. 659, 718-19 (2017).
[v] Naruto v. Slater, 888 F.3d 418 (9th Cir. 2018).
To clients, legal billing can seem “like a black box.” Many clients worry about lawyers overstating their billable hours (“bill padding”) or charging exorbitant hourly rates. By using data analytics to optimize legal billing (“data-driven billing”), law firms can stand out from their competitors and win more business.
1 – Problems that Exist in Legal Billing
Bill Padding
There is cause for concern that legal costs are inflated. Bill padding is partially caused by high billable hours targets. As of 2016, the average associate was required to log 1,892 billable hours per year. These targets “virtually assure[] that some clients will be overbilled.” The economic model that governs law firm billing incentivizes firms to assess lawyers based entirely “upon the ability to generate revenue through the billable hour.” This type of assessment pressures lawyers to bill as many hours as possible. “[P]erceived billing expectations” have led at least some lawyers to inflate their logged billable hours. This sort of fraudulent billing makes law firms look bad and frustrates their clients.
The Cost of a Billable Hour
Despite concerns that billing by the hour may incentivize lawyers to be inefficient, law firms remain “wedded to the billable hour” because of the difficulty in estimating how much time legal work will take. Some firms set prices using cost-based, competition-based, or value-based pricing. Law firms also consider the firm’s expertise in the subject, market rates in the jurisdiction, the type of matter, and the type of client when setting prices. In general, the pricing strategy for many law firms is not data-driven. This lack of optimization suggests that current market prices are likely inflated. The opaqueness of legal billing practices leads to clients dreading the results.
2 – How Data-Driven Billing Can Help
Data-driven billing can help detect bill padding and intelligently set the price of billable hours. Billing software can identify bill padding through “scrutiniz[ing] bills to see irregularities and billing guideline violations” by comparing billable hour submissions against budgets and industry-wide data. Law firms can use pricing analytics to set pricing that will maximize the chance of getting not just a new client but also a profitable one. Using data analytics to minimize bill padding and intelligently set pricing allows law firms to differentiate themselves from competitors and maximize their profitability. “Pricing analytics is a huge untapped opportunity” for law firms. Although clients do not base their decisions purely on price, using data analytics to be an industry leader in pricing can help a law firm stand out in a competitive legal market.
The use of data analytics to analyze legal billing has grown rapidly. In 2014, auditing legal fees was identified as a growth industry. Since then, legal departments have expanded their use of data-driven billing and “have grown increasingly comfortable asking for and analyzing billing-related data.” There are now a large number of private companies that offer data-driven billing software, such as:
- Consilio offers its Sky Analytics software to analyze law firm invoice data to give legal departments cost-savings recommendations.
- Legal Decoder offers its Compliance Engine and Pricing Engine to help firms accurately price legal services to review billable hours and help determine future pricing.
- Lex Machina offers its Legal Analytics service which helps law firms analyze case timing, understand damage exposure, and assess parties’ track records to set competitive pricing.
- Quovant offers its LegalBill spend management tool to help analyze legal spend information.
- Time by Ping offers its automated timekeeping software for lawyers that allows law firms to provide value-based pricing.
3 – How Data-Driven Billing Works
Most data-driven billing software expands upon the Uniform Task-Based Management System (“UTBMS”) legal billing codes used to log billable hours. UTBMS codes were introduced by the American Bar Association in the mid-1990’s to standardize billing practices. While UTBMS codes “brought some clarity” to billing, the codes suffer “significant limitations” because of how broad they are. Legal billing data analytics software can use natural language processing, a form of artificial intelligence, to analyze the text descriptions accompanying time logs to determine exactly what a lawyer was doing and classify it more precisely than the default UTBMS codes can. The analytics software can then compare those classifications against historical data from the law firm and legal industry as a whole to flag potential bill padding. It will also help law firms efficiently price their services by providing them with historical billing data to use when determining pricing. This sort of data-driven pricing could become more important going forward if more law firms begin providing fixed-price quotes to clients instead of using billable hours to determine fees.
To learn more about how data-driven billing works, I spoke with Joe Tiano, the founder and chief executive officer of Legal Decoder. He explained that Legal Decoder uses proprietary natural language processing to analyze billing records and determine what a lawyer did at a more precise level. Legal Decoder has developed a set of proprietary billing categories that are more precise than the standard UTBMS codes. For example, a UTBMS code may indicate that a lawyer was working on a discovery matter, but it will not say whether it was a discovery motion, a deposition, or a motion to compel.
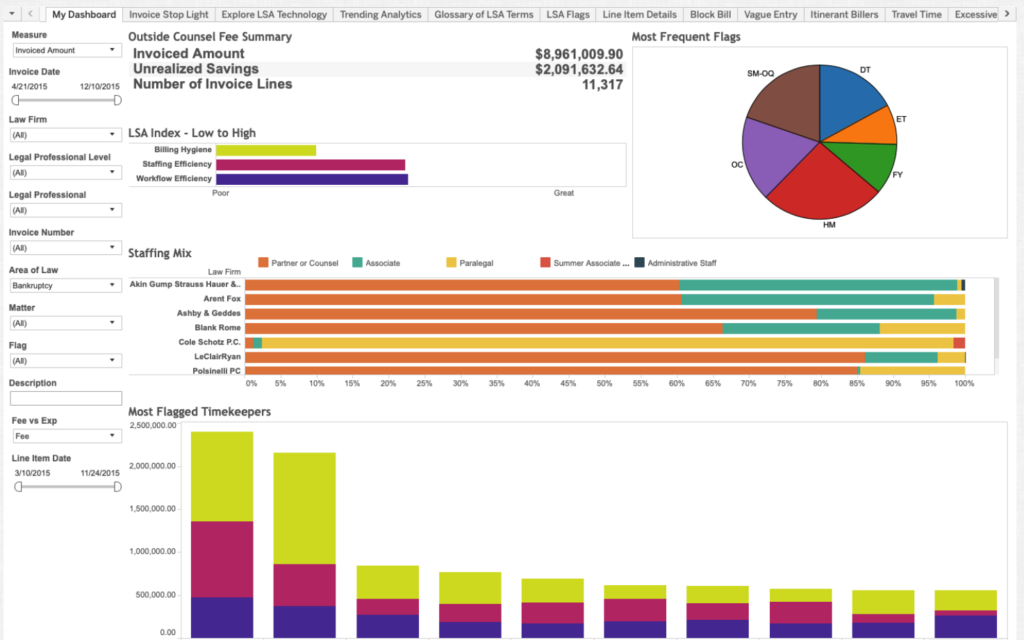
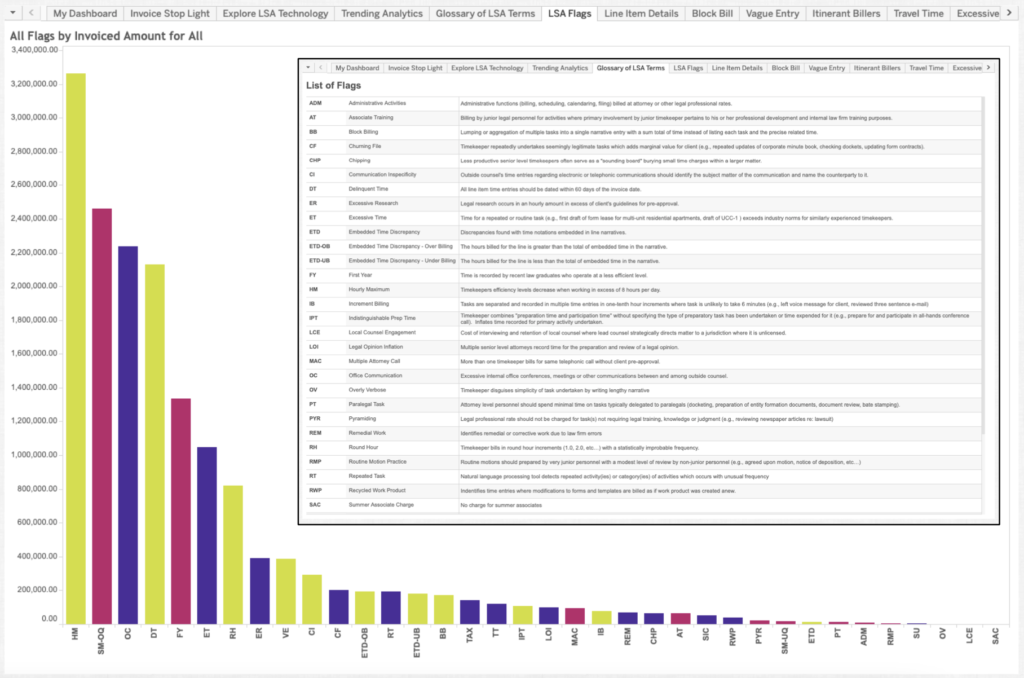
In the process of classifying each billable hour, Legal Decoder’s Compliance Engine looks for three types of problems with legal billing. First, it examines staffing efficiency, which asks whether the most competent and lowest cost lawyer was assigned to a task. For example, the software can detect if a firm is having a partner work on an task that an associate could handle. Second, it examines workflow efficiency, which asks whether a lawyer’s work is redundant or inefficient. Third, it examines billing hygiene, which ensures that the billable hour entries accurately record the time spent on a task.
After Legal Decoder’s proprietary software drills down to precisely classify each billable hour, it then analyzes how long each assignment took. Using historical data from industry-wide benchmarks, Legal Decoder’s Pricing Engine estimates how long each task should take and analyzes whether each matter was handled efficiently. Joe explained that although there can be variance in how long each task will take, the software can, for the most part, effectively estimate how long a task should take. Legal Decoder then presents the results from its Pricing and Compliance Engines in intuitive Tableau dashboards for its clients to analyze.
The following screenshots of the Legal Decoder dashboard were provided courtesy of Joe Tiano. All data displayed in the screenshots are from bankruptcy data and are in the public domain. © 2019 Legal Decoder, Inc. All rights reserved.
4 – How Increased Implementation of Data-Driven Billing Will Impact the Legal Industry
While describing how Legal Decoder’s software works, Joe explained that law firms are sitting on treasure troves of data that they are currently not leveraging. The success of companies like Legal Decoder demonstrates how valuable data-driven billing can be. The continued expansion of applying data analytics to legal billing will likely lead to several changes in the legal industry.
Data-Driven Billing Makes Law Firms More Attractive and Increases Predictability
It may seem like data-driven billing benefits clients and harms law firms by giving clients leverage to negotiate better pricing. Joe pushed back on that idea by explaining that through data-driven billing, law firms can increase their realization rate, which measures the difference between the amount of billable hours logged and what percentage of that time is ultimately paid for by the client. According to Joe’s previous research, as of 2016 roughly $60 billion in billable hours are lost due to the 83% net realization rate across the legal industry. Cost-conscious clients have increasingly begun to push back against what they perceive as inflated bills. In 2015, 68% of law departments received discounted fees by negotiating billing with outside counsel. Inside counsel for clients view receiving a discount as a way to flaunt their efficiency to their chief financial officer. Joe has previously written that by using data analytics to analyze legal billing, law firms can “operate more efficiently (and more profitably) with greater client attraction, retention, and satisfaction.” Put another way, by using data-driven billing, law firms can differentiate themselves from competitors and thus win more business.
Data Analytics Can Affect Partnership Decisions
Data-driven billing gives law firms another way to assess potential partners. Joe explained some of his clients use Legal Decoder’s software to analyze the work of potential partners. Without Legal Decoder’s software, law firms would evaluate an associate based on their total billable hours and overall feedback. Legal Decoder’s software lets law firms drill down into an associate’s billable hours and look for potential issues that would otherwise go unnoticed.
Pricing Will Become a More Important Differentiator in a Post-Covid Market
Most lawyers want to continue working remotely, even when it is safe to return to offices again. Working remotely could allow lawyers to live in lower cost of living areas, allowing firms to pay lower salaries for these lawyers. Law firms are reconsidering their expensive office leases and may look to downsize their square footage in the future. Paying for less office space could lead to law firms lowering their fixed costs. Clients are “smarter than ever before” and have exerted “a continual downward pressure on fees.” All of these trends indicate that pricing will be a more important differentiator between law firms than ever before. Data-driven billing can help a firm stand out by intelligently pricing its services.
Kyle Stenseth is a second-year law student at Northwestern Pritzker School of Law.
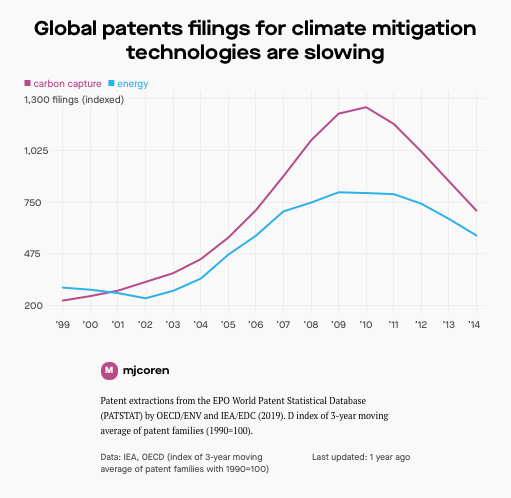
Underlying the U.S. and global patent systems is the belief that granting a limited monopoly will incentivize innovation. Although climate change comes to mind as a particularly controversial topic, according to PEW Research, six in ten Americans and majorities in other surveyed countries see climate change as a major threat. Patent filings seemed to reflect that concern as climate change mitigation technology patents more than doubled between 2005 and 2012. However, beginning in 2012, patent filings for climate change mitigation technologies plummeted— down 44% for carbon capture and storage and 29% for clean energy patents. Why, in a world of increased awareness and acceptance of climate change, did the U.S. and global patent systems fail to deliver on the promise that patents were enough to incentivize innovation?
There are several potential explanations for the green tech patent drop-off. From a technological perspective, there is some evidence that green tech matured quickly and capped, leaving room only for improvement patents. From a policy perspective, many have argued that continued fossil fuel and carbon subsidies, along with the lack of a carbon pricing system, have disincentivized green energy and made it more difficult to compete. From a global market perspective, did the U.S. and China trade war for independence and dominance over the $300B semiconductor market detract from China, which was the largest patentor of green tech, filing patents in the biotech, chemical, and green tech sectors? What is the solution to reversing the green tech patent drop off? From a legal and patent perspective, I argue that the U.S. and global patent systems need to provide fast-tracking for green tech patent applications and reduced standards.
Patent Filings for Climate Change Mitigation Technology Plummeted
As the United States and the rest of the world moved toward embracing technology to remove and reduce carbon emissions, the innovation theorists appeared correct. Worldwide patent filings for climate change mitigation technologies more than doubled between 2005 and 2012. During that period, the growth in the green tech sector was increasing at a faster rate than other technologies. But while technologies in the health, engineering, and information and communication fields continued on their normal trajectories, in 2012 green tech did what few could have anticipated: it defied the innovation push and plummeted. For conservationists and technologists alike, this unexpected nosedive came in the form of a reduction by 44% for carbon capture and storage and 29% for clean energy patents. Only a few related fields avoided this trend: patents that enable power system integration of climate change mitigation and patents for regulated maritime and air vessels.
Possible Causes for the Green Tech Patent Drop-Off
Old technologies are constantly being replaced by new technologies, but in a field that was already heavily digitized (40%) and therefore not needing to be retrofitted, green technology certainly did not appear to be on the verge of a swift exit. There are, however, particular reasons for why green technology patents dropped off.
Technology Perspective: Green Tech Matured and Capped Quickly
First, some energy and economic reports noted that some green technology was uniquely susceptible to maturing and capping earlier in the innovation phase. However, the International Energy Agency surveyed 400 technologies to model commercial readiness and reported the opposite: by 2070, still less than 25% of “key technologies the energy sector needs to reach net-zero emissions” will reach maturity, 41% will be in the early adoption stage, 17% in the demonstration stage, and 17% in the prototype stage. In particular, electricity infrastructure and electrification of heavy industry remain the furthest from zero-carbon maturity.
Policy Perspective: Green Tech Struggling to Compete with Well-Funded Oil and Gas Industries
A second possible cause for the green technology patent drop-off is that less subsidized renewable technologies struggled to compete against heavily funded fossil fuel industries. A nascent and unsubsidized industry that is not yet commercially viable has a much greater likelihood of extinction compared to subsidized industries that are well-established and commercialized. The U.S. Congressional Research Service reported that between 2009 and 2018, renewables received 19% of research and development funding while fossil energy received 21%. However, both are dwarfed by the $100 billion in subsidies or 29% of the R&D funding that nuclear energy received in that same time period. Nonetheless, the relatively similar percentage of R&D funding of renewables and fossil energy may be misleading, at least according to the International Energy Agency, which notes that despite increased urgency, low-carbon energy R&D is actually “below the levels in the 1980s[.]”
Market Perspective: China, the leader in Green Tech Patent Filings, Shifting R&D to Win Semiconductor Trade War with U.S.
A third possible cause for the green technology patent drop-off is less the result of internal U.S. policies, and more the result of external China-U.S. foreign relations. Between 2000-2011, China was leading the global growth in environmentally-related patents with a more than 1,040% increase in applications according to the OECD. Thus, any shifts away from green R&D and patenting would likely be significant. When both the United States and China began to engage in a trade war for greater control over the semiconductor industry, which is the most intensive R&D industry, China doubled down on its plan to invest $118 billion over five years into semiconductors. This US-China trade war may partly explain why China shifted political energy and funding away from green technology and into semiconductors.
Regardless of the initial cause of the shift away from green technology, unlike the U.S., China appears to be on the rebound. Specifically, in 2018-2019, UK commercial law firm EMW reported that China filed 81% of the world’s renewable energy patents, a 28% increase from the year before, compared to the United States, which filed 8% of the world’s renewable energy patents. Additionally, there are some in the semiconductor industry who believe semiconductors can actually play a constructive role in fighting climate change.
How Fast-Tracking Patent Applications for Climate Change Mitigation Technology is the Fastest Way to Reverse This Trend
In order for the U.S. to reverse the trend away from needed and important patent applications for climate change mitigation technology, the U.S. should begin by restarting the Green Technology Pilot Program that it once championed to fast-track these technologies. Before the program ended on March 30, 2012, the USPTO accorded special status to 3,500 applications related to environmental quality, energy conservation, renewable energy development, and greenhouse gas emission reductions. These accelerated examination programs allowed patentees to receive a final disposition within about 12 months. Despite the seemingly premature ending, there remain significant and promising technological inventions that have yet to be widely patented or enabled, including patents in relation to grids, batteries, and carbon capture technology. Because patents are an essential tool to combat climate change, the USPTO and the federal government should actively consider expanding and improving the fast-track process.
The Consequences of Not Fast-Tracking Patent Applications for Climate Change Mitigation Technology Are Dire
According to 98% of climate scientists, the warnings have not been heeded. Much has been discussed about the rapidly deteriorating state of icebergs at the polar caps, and of shifting weather patterns that would result in increased drought, starvation, human migration, and conflict. More innovation and thus more innovators are needed to respond to this growing threat. Innovation needs to be re-injected into green technology: the world does not yet have a fully zero-emission fleet of vehicles; homes are not being constructed with materials that are resilient to increased extreme weather events; it will take years to commercialize fungi to break down plastic; it will take a decade for the alternative meat industry to capture 10% of the market; and it will take until 2040 for the Ocean Cleanup’s proprietary system to clean the Great Pacific Garbage Patch. If the U.S. and the world continue to ignore extreme shifts in climate, green innovators risk losing what traction they have. That is a loss we will all share.
Conclusion
Climate change is a critical problem that requires a solution, but the traditional solution–the patent system–stopped delivering on its essential promise to drive innovation. Beginning in 2012, while climate change awareness and acceptance grew, research and development sputtered. Fewer patents followed, down 44% for carbon capture and storage and 29% for clean energy patents. Various causes may underlie this problem, including some technological limitations, policy prioritization of fossil fuel and nuclear energy, and competing R&D concerns like the semiconductor trade-war. Nonetheless and regardless of the cause, the green technology patent drop-off has gone unnoticed and uncorrected for too long. Here in the U.S., the USPTO and the federal government have an important role to play in finding ways to get the patent system back on track. Fast-tracking green technology patent applications is the best way to accomplish this because time is what the green sector does not have enough of.
Melissa Hurtado is a second-year law student at Northwestern Pritzker School of Law.

Introduction
The COVID-19 pandemic has accelerated the introduction of online learning platforms to elementary and secondary schools across the United States. In many ways, online learning—via Zoom, for example–has presented younger students the opportunity to continue their education during a time when they’re not able to be physically present in a classroom, but online learning has also presented privacy concerns to these students that school districts and parents must grapple with. Virtual education has historically not been offered to younger students, meaning that this is new territory for school districts and parents alike. This post will focus on one major online learning platform, Zoom, and evaluate how it is complying with federal law in this new era of online learning.
Statutory Discussion
This discussion implicates two federal privacy laws. The first is the Children’s Online Privacy Act (“COPPA,” 15 U.S.C. §§ 6501-6505), which was passed in 1998 to “prohibit[] unfair or deceptive acts or practices in connection with the collection, use, and/or disclosure of personal information from and about children on the internet.” Among other things, COPPA requires operators of web sites or online services directed at children
• to provide notice on their web sites of the information it collects from children, how it uses the information, and its disclosure practices;
• to obtain verifiable parental consent prior to any collection, use, and/or disclosure of personal information from children;
• to provide a reasonable means for parents to review the personal information collected from their children and to refuse to permit its further use or maintenance; and,
• to establish and maintain reasonable procedures to protect the confidentiality, security, and integrity of personal information collected from children.
The second implicated law is the Family Educational and Privacy Rights Act (“FERPA,” 20 U.S.C. § 1232g), which gives parents of children under the age of 18 control over their children’s education records. The act defines these records as records, files, documents, and other materials that contain personally identifiable information (“PII”) about a student and that are maintained by an education agency or institution or by a person acting for such agency or institution. In most cases, FERPA prohibits schools from sharing these records with third parties without written permission from a student’s parent.
Given its role as an online learning platform that serves students—including some that are under the age of 13 (the relevant age for COPPA)—in this new era of education, Zoom must comply with both laws.
Zoom’s Privacy Policy
Before the COVID-19 pandemic forced students to switch to online learning, Zoom was a relatively unknown company. Now, it is a household name, offering its services to 90,000 schools across 20 countries as of April 1, 2020. This sudden increase in users has exposed some underlying privacy issues with Zoom, but over the past several months, the company has made changes to its policies to better comply with the relevant laws. To comply with COPPA and FERPA, Zoom has a privacy policy specifically for users of the Zoom Education service. This privacy policy, Zoom for K-12/Primary and Secondary Schools Privacy Statement (“K-12 Privacy Policy”), declares compliance with COPPA and FERPA by enumerating privacy protections for users of the education service that are distinct from the protections listed in the general privacy policy.
Zoom’s COPPA Compliance
As for compliance with COPPA, the K-12 Privacy Policy lists the data the company collects from student users, including “customer content” uploaded to the platform, which can contain information such as files shared by users, meeting transcripts, and chat messages. In addition, Zoom automatically collects information concerning student users’ use of Zoom, including “type and frequency of actions taken, number of logs in or meeting entries, date and time, duration, quantity, quality, network connectivity, other platform performance metrics, and feature usage information, including use of video and screen sharing” and “information about a user’s device, network, and internet connection, such as IP address(es), MAC address, other device ID, device type, operating system type and version, type of camera, microphone and speaker, and client version.”
Pursuant to the COPPA requirement that website operators disclose how data collected from students is used, Zoom states that this information is only used to deliver the functionality of the Zoom platform, to operate the business, and as directed by school subscribers. The student data, according to the K-12 Privacy Policy, is not shared with companies, organizations, or individuals outside of Zoom without consent. Furthermore, Zoom does not permit students, including children under the age of 13, to create K-12 accounts. Instead, school subscribers must provide their students with accounts after obtaining the required parental consent. Lastly, Zoom will share the personal information it collects with individuals when directed to do so by school subscribers, thus creating a method for parents to obtain information collected from their children.
Zoom’s FERPA Compliance
Concerning FERPA, Zoom operates as a “school official” and collects and maintains student PII “on behalf of, and at the direction of, the School Subscriber.” In other words, schools are the owners of the information Zoom collects. Zoom places the onus on the school subscriber to determine how personal information is processed and maintained by requiring the school subscriber to decide which features to utilize in a Zoom meeting (i.e., the recording or chat features—both of which may contain PII) and to decide if the information should be saved in the Zoom Cloud. Additionally, the K-12 Privacy Policy states that this information is only accessed by Zoom upon the documented request of a school subscriber, when required by law, or to improve the platform. If parents wish to access these records or have them deleted, which are their rights according to FERPA, they must go through their child’s school.
Allegations of Noncompliance
Despite asserting compliance with COPPA and FERPA, authorities and school districts have raised concerns in the past several months stating that Zoom is either not complying with these laws or that there are potential security concerns in using the platform. One concern is that Zoom provides a free service which is not subject to the company’s K-12 Privacy Policy. While Zoom’s Privacy Policy claims that the company does not knowingly allow children under the age of 16 to create accounts, the company recently lifted the forty-minute time limit ordinarily placed on its free accounts for K-12 schools that have been closed due to the pandemic. This may encourage schools to utilize the free service, instead of the education service, which will consequently deny students the heightened protections contained in the K-12 Privacy Policy. This fear is not unfounded, because until recently Zoom shared user data that it collected from its free service with third parties, including advertisers. While it is unclear if this data included information collected from minors, if it did, Zoom possibly violated COPPA and FERPA.
Others have raised questions regarding the security of Zoom’s platform, which is of concern since Zoom stores student data and since COPPA requires website operators that serve children to “establish and maintain reasonable procedures to protect the confidentiality, security, and integrity” of the information collected from children. Some instances of security breaches and weaknesses include:
• hackers obtaining and selling 500,000 Zoom passwords; Zoom—for a time—misleadingly reporting that it offers “end-to-end encryption” while in reality only offering “transport encryption”;
• Zoom leaking personal information, including email addresses and photos, to other users on the platform;
• Zoom’s iOS App sending data to Facebook; and, finally,
• trolls hijacking educational sessions and posting hateful messages.
While none of these instances necessarily equate to a violation of COPPA or FERPA, they raise valid concerns over how secure Zoom is as a platform and whether the company is taking reasonable procedures to protect the information it collects from children.
Conclusion
In sum, in this new age of education, Zoom has seen a rapid increase in users which has exposed several flaws in the platform’s privacy policies and practices. But regardless of this sudden increase, Zoom has an obligation to comply with COPPA and FERPA and to protect the information it gathers from students. While the company’s privacy policies proclaim compliance with these laws, it is vital that government officials continue to police the platform to ensure that children’s privacy and education records are safeguarded, as required by COPPA and FERPA.
Steve Komorek is a second-year law student at Northwestern Pritzker School of Law.

From the moment you wake up and check social media to the moment you end your day by streaming the latest binge-worthy TV show, chances are high that an algorithm is hard at work to help curate your “best life.” But the stakes are changing. Instead of simply recommending certain articles to read or movies to watch, algorithms are now increasingly being utilized to make much more impactful decisions in areas such as criminal justice or healthcare.
As a result, implementing a public policy that focuses on algorithmic accountability is becoming progressively more important. Ideally, such a policy would regulate the actions of both the private and public sectors with full and open transparency. By adopting a framework of public disclosure in a way that is similar to how the Securities and Exchange Commission currently regulates the financial markets, thoughtful leaders may be able to draft better legislation to achieve algorithmic accountability.
The 2019 Algorithmic Accountability Act (the Act) is the first national attempt at regulating algorithms, but as first attempts go, the Act produced more lessons learned and questions than actionable law. So far, critics have pointed out a need to reframe the issues as a means to better define what types of algorithms legislation should cover. For example, the size of a company may have little to do with the impact of an algorithm-assisted decision regarding the benefits of thousands, yet the size of a company is factored heavily in the Act. Others want to start from a broader perspective, suggesting legislators should begin by developing an algorithmic bill of rights. However, there is a serious issue with transparency in the Act that warrants at least as much attention as any other issue.
In the Act, the issue of transparency boils down to the optional nature of disclosing impact assessments of algorithms, or “automated decision systems,” to the public. For example, according to DataInnovation.org, impact assessments may help “evaluate how an automated system is designed and used—including the training data it relies on, the risks a system poses to privacy or security, and various other factors.” But ultimately, accountability takes a tumble because the Act allows impact assessments to be “made public by the covered entity at its sole discretion.” In other words, if a company deploys an automated decision system (ADS) that has serious privacy and security concerns, the public may never know about it. When considering that we live in a time where public scrutiny often tips the scales, the optional nature of disclosure hardly seems adequate.
To address issues of transparency, the Securities and Exchange Commission (SEC) may provide a model framework. In the U.S., the SEC is an agency that regulates how and what financial information companies must disclose to the public. However, the SEC does not determine whether any given company is good or bad. Instead, the responsibility of checking financial performance is ultimately shouldered by experts in the market. Similarly, for algorithms, regulators should consider enforcing a policy of mandatory disclosure while leveraging the power of the markets to collectively achieve accountability.
Public Sector Issues with Algorithms
Although both governments and companies have well-documented issues in deploying ADS, the 2019 Algorithmic Accountability Act curiously does not appear to cover government actions. However, if algorithms are deployed to help manage public benefits, omitting governments from regulatory oversight is a mistake that undercuts the premise of transparency.
The case study of Barry v. Lyon, 834 F.3d 706 (6th Cir. 2016), serves as just one example of why government actions must be regulated for algorithmic accountability. As profiled by the Litigating Algorithms 2019 US Report, the Michigan Department of Health and Human Services (MDHHS) deployed an algorithm to “automatically disqualify individuals from food assistance based on outstanding felony warrants.” However, the algorithm failed at technical, business, and legal levels.
The MDHHS algorithm demonstrated technical failure as it “improperly matched more than 19,000 Michigan residents, and automatically disqualified them from food assistance benefits with a vague notice.” Moreover, the algorithm failed a basic business logic test when Michigan projected it would cost $345,000 but produce “virtually no state savings.” From a legal perspective, courts eventually ruled that Michigan’s practices violated Federal statutes, the Supremacy Clause, and Constitutional due process requirements.
In the end, the state government paid for an algorithm that did not work and reversed decisions on benefits, while also paying out $3,120 to each class member who was unlawfully disqualified. Most importantly, real people suffered through years of lost benefits.
What if, instead, government agencies were subject to information disclosure requirements when deploying ADS in the same way that private sector companies must disclose their financial information to the SEC? Perhaps public scrutiny or the anticipation of such scrutiny could help other governments from becoming a MDHHS case study in the future.
Private Sector Issues with Algorithms
The government is not alone in failing to deploy an algorithm successfully. Private sector juggernauts, such as IBM and Microsoft, have also failed with their own ventures.
Joy Buolamwini’s research revealed that Microsoft and IBM released facial recognition algorithms that could detect the faces of men with light skin tones quite well but erred when detecting the faces of women with dark skin tones. In fact, in order to be recognized by cameras that used the facial recognition algorithms, Buolamwini had to put on a white mask. Aside from the obvious issues, a central problem with this case is that when Microsoft and IBM released these algorithms to the public without any disclosures, the algorithmic bias was unknowingly perpetuated.
How would things be different if Microsoft and IBM publicly disclosed benchmarks about their algorithms before external researchers exposed their biases? While it is difficult to speculate about the past, a public disclosure policy might have impacted Microsoft and IBM in a manner that is similar to how product liability currently works for consumer goods. Consider how one could apply product liability laws, which impose certain duties on producers, to the regulation of AI. For example, companies might have a duty to warn and subsequently a duty to test and disclose issues with their algorithms. Under this hypothetical framework, perhaps Microsoft and IBM could have avoided a public relations issue and released a better product. Further, researchers like Buolamwini, and camera manufacturers who implemented the algorithm in their products, would have had the opportunity to make a more informed decision about whether to use or improve the algorithms.
Conceivably, product-liability-inspired policy that follows the structure of the SEC disclosure regime could be the solution. Such public disclosure for tech companies is not new. Under the banner of protecting investors, companies like Microsoft and IBM submit financial disclosures to the SEC at least every quarter, and emerging companies go through extensive disclosure protocols when they go public in IPOs. Why can’t we protect consumers from harmful algorithms in the same way?
Regulating for Algorithmic Accountability
To regulate for algorithmic accountability, a future act should incorporate a policy of mandatory public disclosure in combination with the concept of product liability as a means to achieve algorithmic accountability. Such a policy would cover both public and private sector entities and require them to disclose how their algorithms are trained, what the intended uses are, and their associated performance benchmarks. Moreover, as algorithms learn and evolve from processing data, we should expect publicly available and understandable updates on how algorithms make or recommend decisions.
Challenges with a Disclosure Framework
Despite the potential advantages of pursuing a policy of public disclosure, there are a number of additional problems to consider. From the Great Depression to the Great Recession, information disclosure and regulation regimes have had a history of spectacular failures. However, we should see the following as a list of challenges to overcome rather than a list of excuses not to pursue the disclosure framework.
• Irrational Markets: People do not always behave rationally, and information disclosure may not prevent misuse—how do we manage bad actors and unintended outcomes?
• Privacy Concerns: Mandating information disclosure does not have to be mutually exclusive with privacy—how do we balance the two?
• Cost of Accountability: Registering securities in the United States is currently an expensive and resource-intensive endeavor—how can we make algorithmic registration an efficient process?
• Exemptions: Part of the complexity in securities regulation is understanding how to perfect an exemption—how can we determine what entities and what types of algorithmic decision-making systems to cover?
• Intellectual Property Rights: Companies like Coca-Cola have patents, trade secrets, copyrights, and trademarks, yet they still participate in the disclosure process for securities regulation—how can we protect intellectual property rights with a disclosure system?
• Product Liability: Laws governing product liability are existing examples of information disclosure that may apply to algorithmic accountability—how do efforts to regulate algorithms cross over?
Conclusion
Over the past decade, algorithms have permeated nearly every aspect of our lives. Since this article was first drafted in early 2020, the novel coronavirus (COVID-19) emerged to drastically change the world. Since then, COVID-19 has ushered in a new level of acceptance and even demand for more intrusive and sophisticated algorithms to help with tasks such as contact tracing. While there are presently more pressing issues concerning the larger economy and the health and wellness of frontline workers, there has also never been a more pressing need for algorithmic accountability. As legislators continue to explore different regulatory schemes, they should consider incorporating a policy of public information disclosure that promotes transparency as a pillar to ensure algorithmic accountability in both the public and private sectors.
Justin Chae is a Master of Science in Law student at Northwestern Pritzker School of Law.